Hadoop简介
- Hadoop是开源社区Apache的一个基于廉价商业硬件集群和开放标准的分布式数据存储及处理平台,也是事实上的大数据计算标准。
Hadoop系统架构
- 从系统架构角度看,Hadoop通常部署在低成本的Intel/Linux硬件平台上,由多台服务器通过高速局域网构成一个计算集群,在各个结点上运行Linux操作系统。
- Hadoop集群系统架构:
Hadoop三大主要模式
- Hadoop在安装和运行时由三种模式可供选择:单机模式
- 单机模式(Standalone mode):
- Hadoop安装时的默认模式,不对配置文件进行修改进入的模式;
- 使用本地文件系统;
- 不启动NameNode、DataNode、JobTracker、TaskTracker等守护进程;
- 用来对MapReduce程序进行查错和调试的模式。
- 虚拟(伪)分布模式(pseudo-distributed mode):
- 在一台机器上用软件模拟多节点集群,每个守护进程都以Java进程形式运行;
- 与单机模式比较增加了代码调试功能,允许检查内存使用情况和读写HDFS文件系统。
- 这一模式需要修改三个配置文件才能进入:
core-site.xml、hdfs-site.xml、mapred-site.xml
- 完全分布模式(completely distributed Mode):实际生产采用的模式
- Hadoop安装运行在多台主机上,构成一个真实的Hadoop集群,在所有节点上安装JDK和Hadoop,相互通过高速局域网连接;
- 各节点间设置SSH免密码登录,将各个从节点生成的公钥添加到主节点的信任列表。
- 这一模式也需要修改三个配置文件才能进入:
core-site.xml、hdfs-site.xml、mapred-site.xml
Hadoop集群配置
- 硬件配置:Hadoop集群内的计算节点类型实际只有两类。
- NameNode:执行作业调度、资源分配、系统监控等任务的节点。
- DateNode:承担具体的数据计算任务。
- 软件配置:
- Linux操作系统
- JDK
- SSH(Security Shell)安全协议:Hadoop NameNode需要启动集群中的所有节点的守护进程,而这个远程调用需要通过SSH无密码登录来实现。
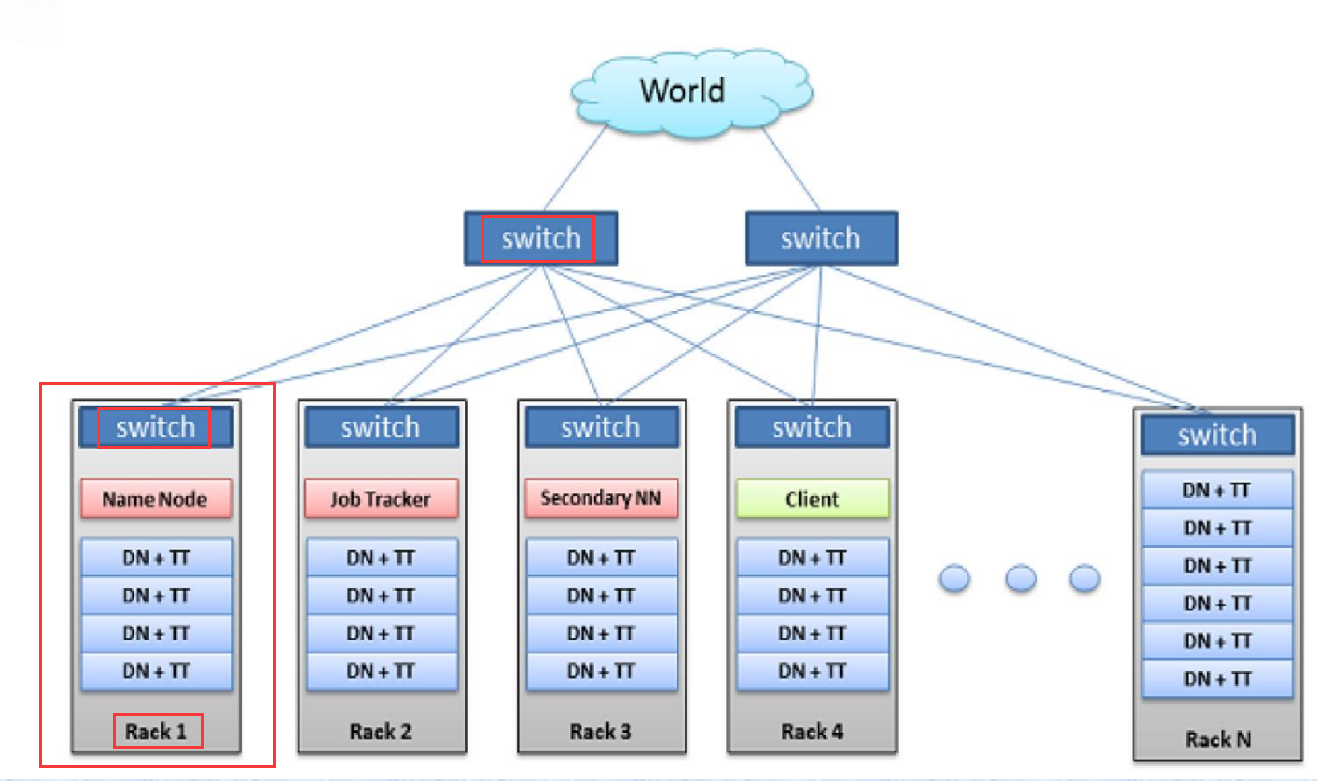
- 网络配置:常规Hadoop集群包含两层网络结构。
- NameNode到机架(Rack)的网络连接
- 机架内部的DataNode之间的网络连接。
- Hadoop集群的网络拓扑:

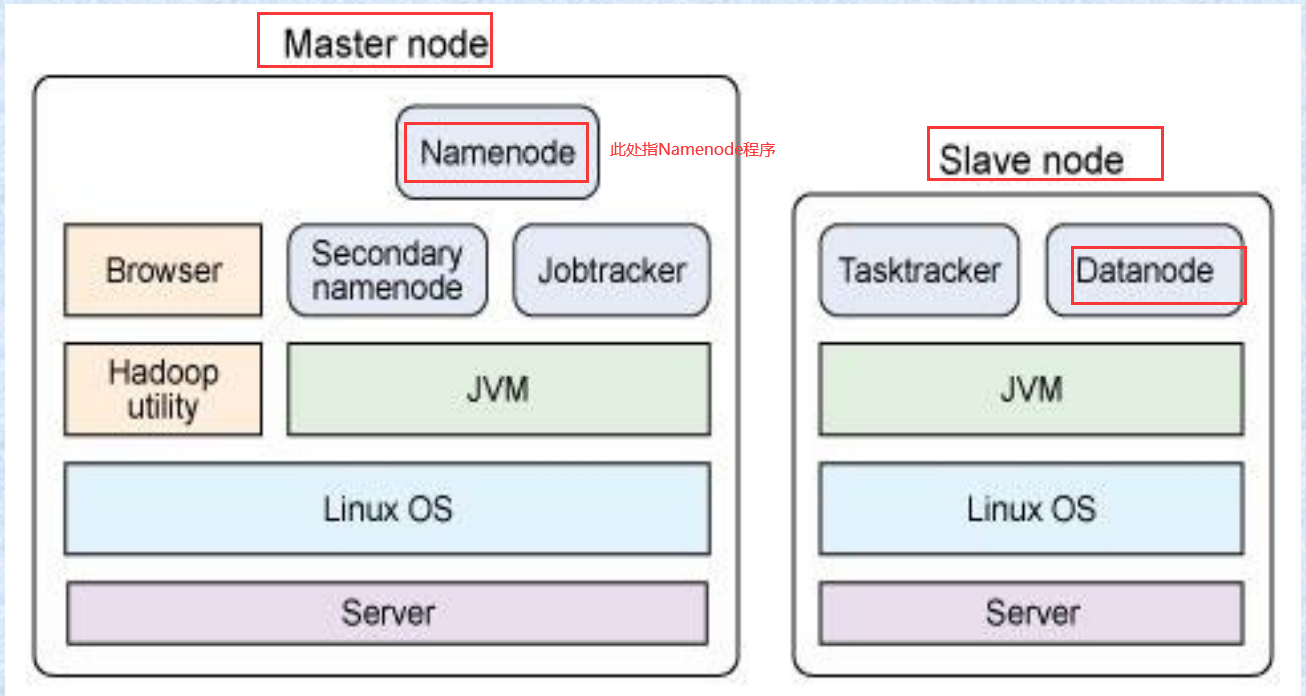
- Hadoop节点上的软件部署情况:
- 主节点上的程序提供Hadoop集群管理、协调和资源调度功能
- 从节点上的程序主要实现HDFS文件系统存储功能和节点数据处理功能。
Hadoop生态系统
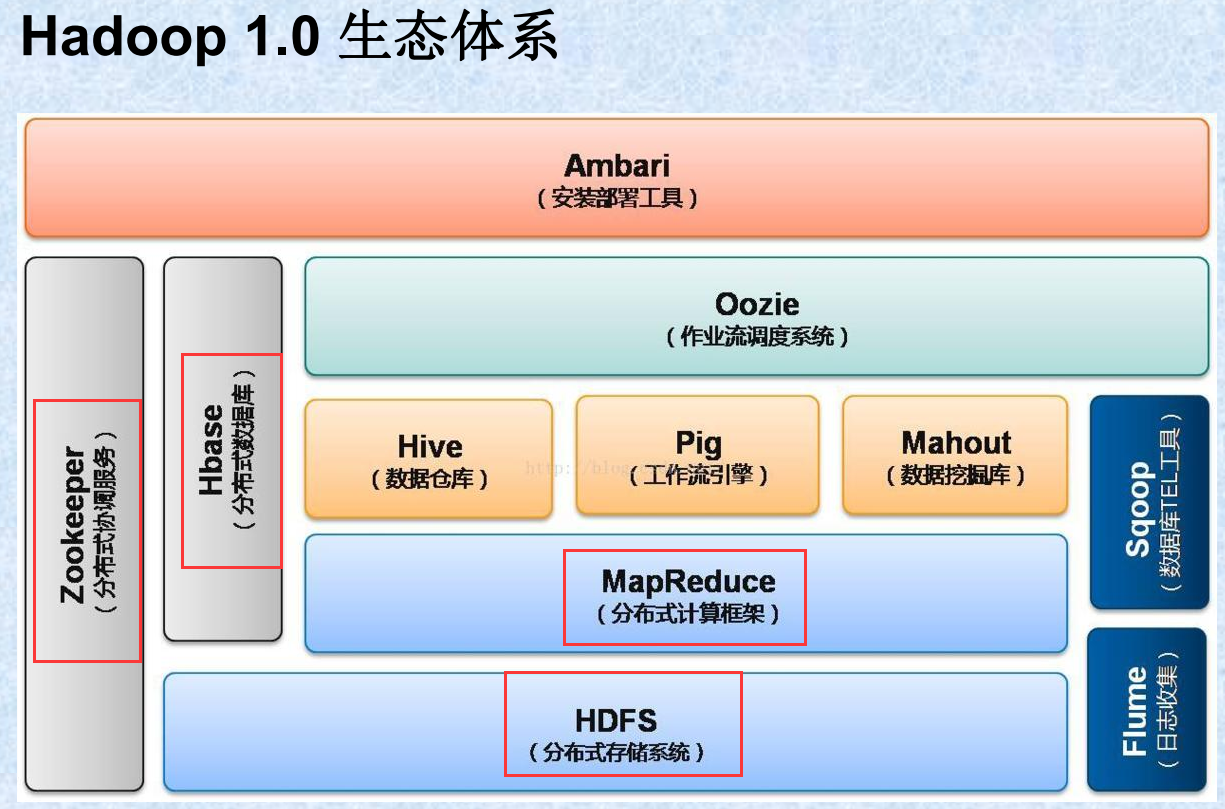
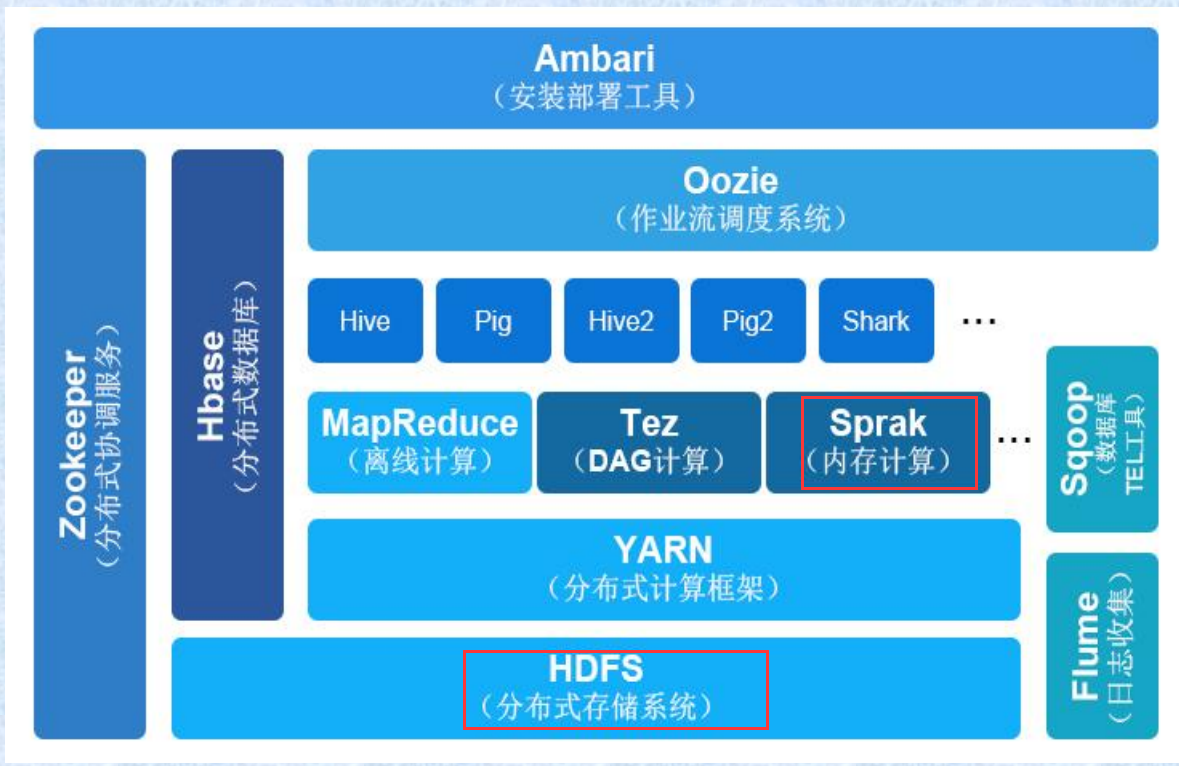
- Hadoop平台的核心部分为HDFS(提供海量数据存储功能)和MapReduce(提供数据处理功能)。后来的2.0版本又加入了YARN(集群资源管理器)及其他多种开发工具包。
- 基于HDFS/HBase的数据存储系统
- 基于YARN/Zookeeper的管理调度系统。
- 支持不同计算模式的处理引擎。
- 主节点运行的程序或进程:
- 主节点程序Namenode
- Jobtracker 守护进程
- 管理集群所用的Hadoop 工具程序和集群监控浏览器
- 从节点运行的程序:
- 从节点程序Datanode
- 任务管理进程Tasktracker
- 区别:
- 主节点程序提供 Hadoop 集群管理、协调和资源调度功能
- 从节点程序主要实现 Hadoop 文件系统(HDFS)存储功能和节点数据处理功能。
- Hadoop1.0生态体系:
- Hadoop2.0生态体系:
- Hadoop数据存储系统构件:
- 分布式文件系统HDFS(Hadoop Distributed File System)。HDFS文件系统构成了Hadoop数据存储体系的基础。
- 分布式非关系型数据库Hbase
- 数据仓库及数据分析工具Hive和Pig
- 用于数据采集、转移和汇总的工具Sqoop和Flume。
- Hadoop管理调度系统构件:
- Zookeeper:提供分布式协调服务管理
- Oozie:负责作业调度
- Ambari:提供集群配置、管理和监控功能
- Chukwa:大型集群监控系统
- YARN:集群资源调度管理系统