线性回归
- 回归(regression)是指一类为一个或多个自变量与因变量之间关系建模的方法。在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
- 当我们想预测一个数值时,就会涉及到回归问题。常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人)、预测需求(零售销量)等。
线性回归的基本元素
- 线性回归(linear regression)在回归的各种标准工具中最简单而且最流行。
- 线性回归基于几个简单的假设:首先,假设自变量和因变量之间的关系是线性的,即可以表示为中元素的加权和,这里通常允许包含观测值的一些噪声;其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
- 为了解释线性回归,我们举一个实际的例子:
- 问题:我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。
- 数据集:为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。这个数据集包括了房屋的销售价格、面积和房龄。
- 训练集与样本:在机器学习的术语中,该数据集称为训练数据集(training data set)或训练集(training set),每行数据(在这个例子中是与一次房屋交易相对应的数据)称为样本(sample),也可以称为数据点(data point)或数据样本(data instance)。
- 目标:我们要试图预测的目标(在这个例子中是房屋价格)称为标签(label)或目标(target)。
- 特征:预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
- 通常,我们使用来表示数据集中的样本数。对索引为的样本,其输入表示为,其对应的标签是。
线性模型
-
线性假设是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和(即线性函数),如下面的式子:
- 权重与偏移量:上式中的和称为权重(weight),称为偏置(bias),或称为偏移量(offset)、截距(intercept)。
- 权重决定了每个特征对我们预测值的影响。
- 偏置是指当所有特征都取值为0时,预测值应该为多少。即使现实中不会有任何房子的面积是0或房龄正好是0年,我们仍然需要偏置项。如果没有偏置项,我们模型的表达能力将受到限制。
- 仿射变换:上式也可以说是是输入特征的一个仿射变换(affine transformation)。仿射变换的特点是通过加权和对特征进行线性变换(linear transformation),并通过偏置项来进行平移(translation)。
-
模型目标:给定一个数据集,我们的目标是寻找模型的权重和偏置,使得根据模型做出的预测大体符合数据里的真实价格。输出的预测值由输入特征通过线性模型的仿射变换决定,仿射变换由所选权重和偏置确定。
-
用向量表示线性函数:当关注有少量特征的数据集。在这些学科中,建模时经常像这样通过长形式显式地表达。而在机器学习领域,我们通常使用的是高维数据集,建模时采用线性代数表示法会比较方便。当我们的输入包含个特征时,我们将预测结果(通常使用“尖角”符号表示估计值)表示为:
- 将所有特征放到向量中,并将所有权重放到向量中,我们可以用点积形式来简洁地表达模型:
-
在上式中,向量对应于单个数据样本的特征。用符号表示的矩阵可以很方便地引用我们整个数据集的个样本。其中,的每一行是一个样本,每一列是一种特征。
-
对于特征集合,预测值可以通过矩阵-向量乘法表示为:
-
给定训练数据特征和对应的已知标签,线性回归的目标是找到一组权重向量和偏置。当给定从的同分布中取样的新样本特征时,找到的权重向量和偏置能够使得新样本预测标签的误差尽可能小。
-
在我们开始寻找最好的模型参数(model parameters)和之前,我们还需要两个东西:(1)一种模型质量的度量方式;(2)一种能够更新模型以提高模型预测质量的方法。
损失函数
-
拟合程度的度量:在我们开始考虑如何用模型拟合(fit)数据之前,我们需要确定一个拟合程度的度量。损失函数能够量化目标的实际值与预测值之间的差距,作为拟合程度的度量。
-
损失函数的实质就是自变量为模型的参数,函数值(因变量)为模型的误差值的函数。
-
通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。回归问题中最常用的损失函数是平方误差(差的平方)函数。当样本的预测值为,其相应的真实标签为时,平方误差可以定义为以下公式:
$$l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y{(i)}\right)2.$$
-
常数不会带来本质的差别,但这样在形式上稍微简单一些,表现为当我们对损失函数求导后常数系数为1。
-
由于平方误差函数中的二次方项,估计值和观测值之间较大的差异将贡献更大的损失。为了度量模型在整个数据集上的质量,我们需计算在训练集个样本上的损失均值(也等价于求和)。
-
损失函数度量单个样本的训练情况,损失均值(更多的时候是对全部损失函数进行专门计算的成本函数)度量整个样本集的训练情况。
-
-
在训练模型时,我们希望寻找一组参数(),这组参数能最小化在所有训练样本上的总损失。如下式:
$$\mathbf{w}^, b^ = \operatorname*{argmin}_{\mathbf{w}, b}\ L(\mathbf{w}, b).$$
解析解
- 线性回归的解可以用一个公式简单地表达出来,这类解叫作解析解(analytical solution)。解析解就是直接解方程,将参数用自变量和因变量表示出来。不常用的原因就是因为,很多模型函数是无法直接解出参数的表示方程的。
- 首先,我们将偏置合并到参数中。合并方法是在包含所有参数的矩阵中附加一列。我们的预测问题是最小化。这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失最小值。将损失关于的导数设为0,得到解析解(闭合形式):
- 像线性回归这样的简单问题存在解析解,但并不是所有的问题都存在解析解。解析解可以进行很好的数学分析,但解析解的限制很严格,导致它无法应用在深度学习里。
小批量随机梯度下降
-
本书中我们用到一种名为**梯度下降(gradient descent)**的方法,这种方法几乎可以优化所有深度学习模型。它通过不断地在损失函数递减的方向上更新参数来降低误差。
-
小批量随机梯度下降(minibatch stochastic gradient descent):
- 梯度下降:最简单的用法是计算损失函数(数据集中所有样本的损失均值)关于模型参数的导数(在这里也可以称为梯度)。梯度下降的实质就是根据函数的导数(梯度、偏导数)来求函数的最值,因为损失函数的自变量为模型的参数,所以就实际是找到使误差值最小的模型参数值。
- 小批量:但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本。
-
计算方法:在每次迭代中,我们首先随机抽样一个小批量,它是由固定数量的训练样本组成的。然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。最后,我们将梯度乘以一个预先确定的正数,并从当前参数的值中减掉。我们用下面的数学公式来表示这一更新过程(表示偏导数):
- 算法的步骤如下:
- 初始化模型参数的值,如随机初始化;
- 从数据集中随机抽取小批量样本且在负梯度的方向上更新参数,并不断迭代这一步骤。对于平方损失和仿射变换,我们可以明确地写成如下形式:
- 算法的步骤如下:
-
超参数:上式中的和都是向量。在这里,更优雅的向量表示法比系数表示法(如)更具可读性。表示每个小批量中的样本数,这也称为批量大小(batch size)。表示学习率(learning rate)。批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter)。
-
调参(hyperparameter tuning):是选择超参数的过程。超参数通常是我们根据训练迭代结果来调整的,而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。
-
获取模型参数估计值:在训练了预先确定的若干迭代次数后(或者直到满足某些其他停止条件后),我们记录下模型参数的估计值,表示为。但是,即使我们的函数确实是线性的且无噪声,这些估计值也不会使损失函数真正地达到最小值。因为算法会使得损失向最小值缓慢收敛,但却不能在有限的步数内非常精确地达到最小值。
用学习后模型进行预测
- 给定学习到的线性回归模型,现在我们可以通过给定的房屋面积和房龄来估计一个未包含在训练数据中的新房屋价格。
- 给定特征估计目标的过程通常称为预测(prediction)或推断(inference)。
矢量化加速
- 在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。为了实现这一点,需要(我们对计算进行矢量化,从而利用线性代数库,而不是在Python中编写开销高昂的for循环)。
import math
import time
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt- 为了说明矢量化为什么如此重要,我们考虑(对向量相加的两种方法)。
- 我们实例化两个全1的10000维向量。在一种方法中,我们将使用Python的for循环遍历向量。在另一种方法中,我们将依赖对向量
+运算的调用。
n = 10000
a = tf.ones(n)
b = tf.ones(n)- 定义一个计时器:
class Timer: #@save
"""记录多次运行时间。"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器。"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中。"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间。"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和。"""
return sum(self.times)
def cumsum(self):
"""返回累计时间。"""
return np.array(self.times).cumsum().tolist()- 首先,[我们使用for循环,每次执行对应位相加的加法]。
c = tf.Variable(tf.zeros(n))
timer = Timer()
for i in range(n):
c[i].assign(a[i] + b[i]) #assign函数用新计算的值替换当前的位置的值
f'{timer.stop():.5f} sec' #转化为字符串显示'5.68500 sec'
- 或者,我们使用重载的
+运算符来计算按元素的和。
timer.start()
d = a + b
f'{timer.stop():.5f} sec''0.00100 sec'
- 结果很明显,第二种方法比第一种方法快得多。矢量化代码通常会带来数量级的加速。另外,我们将更多的数学运算放到库中,而无须自己编写那么多的计算,从而减少了出错的可能性。
正态分布与平方损失
- 正态分布和线性回归之间的关系很密切。简单的说,若随机变量具有均值和方差(标准差),其正态分布概率密度函数如下:
- 下面[我们定义一个Python函数来计算正态分布]。
def normal(x, mu, sigma):
p = 1 / math.sqrt(2 * math.pi * sigma**2)
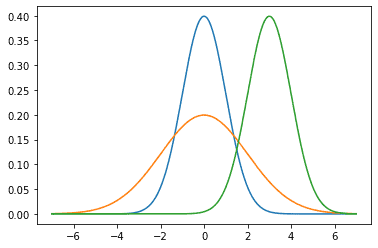
return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)我们现在(可视化正态分布)。
# 再次使用numpy进行可视化
x = np.arange(-7, 7, 0.01) # 从-7 到 7 以0.01为步频的一系列数字
# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)] # 第一个为均值mu,第二个为标准差sigma
ys = []
for mu, sigma in params:
y = normal(x, mu, sigma)
ys.append(y)
plt.plot(x, ys[0], x, ys[1], x, ys[2])[<matplotlib.lines.Line2D at 0x2100287a550>,
<matplotlib.lines.Line2D at 0x2100287a610>,
<matplotlib.lines.Line2D at 0x2100287a6d0>]
-
就像我们所看到的,改变均值会产生沿轴的偏移,增加方差将会分散分布、降低其峰值。
-
均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:我们假设了观测中包含噪声,其中噪声服从正态分布。噪声正态分布如下式:
-
因此,我们现在可以写出通过给定的观测到特定的可能性(likelihood):
-
根据最大似然估计法,参数和的最优值是使整个数据集的可能性最大的值,根据最大似然估计法选择的估计量称为最大似然估计量:
-
虽然使许多指数函数的乘积最大化看起来很困难,但是我们可以在不改变目标的前提下,通过最大化似然对数来简化。由于历史原因,优化通常是说最小化而不是最大化。我们可以改为最小化负对数似然。由此可以得到的数学公式是:
-
现在我们只需要假设是某个固定常数就可以忽略第一项,因为第一项不依赖于和。现在第二项除了常数外,其余部分和前面介绍的平方误差损失是一样的。幸运的是,上面式子的解并不依赖于。因此,在高斯噪声的假设下,最小化均方误差等价于对线性模型的最大似然估计。
从线性回归到深度网络
- 尽管神经网络涵盖了更多更为丰富的模型,我们依然可以用描述神经网络的方式来描述线性模型,从而把线性模型看作一个神经网络。
- 可以用“层”符号来重写这个模型。
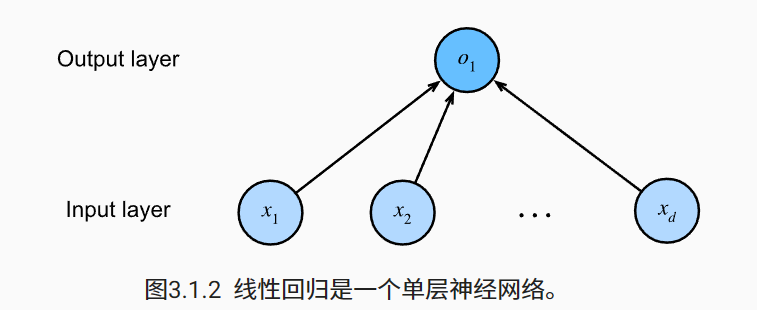
神经网络图
- 在下图中,我们将线性回归模型描述为一个神经网络。需要注意的是,该图只显示连接模式,即只显示每个输入如何连接到输出,隐去了权重和偏置的值。
-
在如图所示的神经网络中,输入为,因此输入层中的输入数(或称为特征维度,feature dimensionality)为。网络的输出为,因此输出层中的输出数是1。需要注意的是,输入值都是已经给定的,并且只有一个计算神经元。由于模型重点在发生计算的地方,所以通常我们在计算层数时不考虑输入层。也就是说, 上图中神经网络的层数为1。我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
-
全连接层:对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连,我们将这种变换( 上图中的输出层)称为全连接层(fully-connected layer),或称为稠密层(dense layer)。
线性回归的从零开始实现
- 在了解线性回归的关键思想之后,我们可以开始通过代码来动手实现线性回归了。我们将从零开始实现整个方法,包括数据流水线、模型、损失函数和小批量随机梯度下降优化器。虽然现代的深度学习框架几乎可以自动化地进行所有这些工作,但从零开始实现可以确保你真正知道自己在做什么。同时,了解更细致的工作原理将方便我们自定义模型、自定义层或自定义损失函数。我们将只使用张量和自动求导。
import random
import tensorflow as tf
import matplotlib.pyplot as plt生成数据集
-
我们将[根据带有噪声的线性模型构造一个人造数据集。]我们的任务是使用这个有限样本的数据集来恢复这个模型的参数。我们将使用低维数据,这样可以很容易地将其可视化。
-
在下面的代码中,我们生成一个包含1000个样本的数据集,每个样本包含从标准正态分布中采样的2个特征。我们的合成数据集是一个矩阵。
-
使用线性模型参数、和噪声项生成数据集及其标签:
-
可以视为捕获特征和标签时的潜在观测误差,加上误差使数据更加符合真实情况。在这里我们认为标准假设成立,即服从均值为0的正态分布。为了简化问题,我们将标准差设为0.01。下面的代码生成合成数据集。
#根据数据集以及线性模型得出对应的y值向量
def synthetic_data(w, b, num_examples): # w为线性模型参数,b为偏移量,num_examples是数据集数据数量
"""生成 y = Xw + b + 噪声。"""
X = tf.zeros((num_examples, w.shape[0])) # 生成和w的列数一样,行数为num_examples的,值全为0矩阵
X += tf.random.normal(shape=X.shape) # 用标准正态分布的数值为X矩阵的每个元素赋值
# 将w转换为2行1列(-1代表自动推断此处应该填的维数)的矩阵与X矩阵相乘再加上偏移量计算y
y = tf.matmul(X, tf.reshape(w, (-1, 1))) + b
y += tf.random.normal(shape=y.shape, stddev=0.01) # 给y的值加上服从正态分布的误差
y = tf.reshape(y, (-1, 1)) # 将y转换为1列的矩阵
return X, ytrue_w = tf.constant([2, -3.4]) # 生成值为2,-3.4的数组
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000) features是特征向量组,其中的每一行都包含一个二维数据样本,labels是标签向量组,其中的每一行都包含一维标签值(一个标量)。
# 查看两个向量组的维数情况
print('features:', features[0],'\nlabel:', labels[0])features: tf.Tensor([ 0.7173423 -0.87579876], shape=(2,), dtype=float32)
label: tf.Tensor([8.623853], shape=(1,), dtype=float32)
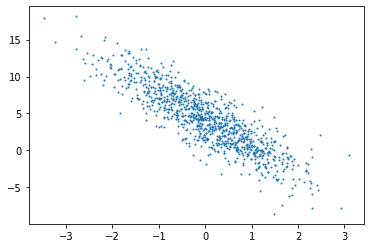
- 通过生成第二个特征
features[:, 1]和labels的散点图,可以直观地观察到两者之间的线性关系。 (features[:,1]指取矩阵第1列(0,1两列)的全部数值作为x轴的取值
plt.scatter(features[:, (1)].numpy(), labels.numpy(), 1)<matplotlib.collections.PathCollection at 0x1b336bab400>
读取数据集
- 训练模型时要对数据集进行遍历,每次抽取一小批量样本,并使用它们来更新我们的模型。由于这个过程是训练机器学习算法的基础,所以有必要定义一个函数,该函数能打乱数据集中的样本并以小批量方式获取数据。
- 在下面的代码中,我们[定义一个
data_iter函数,该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量]。每个小批量包含一组特征和标签。 - 注:yield用法解析
def data_iter(batch_size, features, labels): # 将传入的特征值矩阵和标签矩阵每次取出一小批用来训练,直到取完
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices) # 打乱列表数字的顺序实现随机读取
for i in range(0, num_examples, batch_size): # 获取从0到numexamples的数字,以batch_size为步频
j = tf.constant(indices[i: min(i + batch_size, num_examples)])#从indices中获取从i到i+batch_size的数字生成向量
# 使用yield迭代返回每一次提取的小批量向量
yield tf.gather(features, j), tf.gather(labels, j) # 将两个矩阵中下标对应j向量的的值取出来形成一个新向量- 通常,我们使用合理大小的小批量来利用GPU硬件的优势,因为GPU在并行处理方面表现出色。每个样本都可以并行地进行模型计算,且每个样本损失函数的梯度也可以被并行地计算,GPU可以在处理几百个样本时,所花费的时间不比处理一个样本时多太多。
- 下面读取第一个小批量数据样本并打印:每个批量的特征维度说明了批量大小和输入特征数。同样的,批量的标签形状与
batch_size相等。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
breaktf.Tensor(
[[-0.92631394 0.5370933 ]
[-0.563874 1.3515444 ]
[-1.0858414 0.7342149 ]
[-0.6196944 2.1207151 ]
[ 0.25010496 -2.0217266 ]
[-0.60749346 -0.30016303]
[-0.14507185 -1.2292194 ]
[ 0.00904182 1.0107433 ]
[ 0.1355916 2.2240083 ]
[ 2.351774 0.6235444 ]], shape=(10, 2), dtype=float32)
tf.Tensor(
[[ 0.518868 ]
[-1.5353174 ]
[-0.46222487]
[-4.2567196 ]
[11.557878 ]
[ 4.0018907 ]
[ 8.08824 ]
[ 0.7906476 ]
[-3.0673254 ]
[ 6.7880654 ]], shape=(10, 1), dtype=float32)
- 当我们运行迭代时,我们会连续地获得不同的小批量,直至遍历完整个数据集。
初始化模型参数
- 在我们开始用小批量随机梯度下降优化我们的模型参数之前,我们需要先有一些参数。在下面的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重,并将偏移量初始化为0。
- 注:tf.Variable用法解析
w = tf.Variable(tf.random.normal(shape=(2, 1), mean=0, stddev=0.01),
trainable=True)
b = tf.Variable(tf.zeros(1), trainable=True)
w,b(<tf.Variable 'Variable:0' shape=(2, 1) dtype=float32, numpy=
array([[-0.00593151],
[ 0.00970709]], dtype=float32)>,
<tf.Variable 'Variable:0' shape=(1,) dtype=float32, numpy=array([0.], dtype=float32)>)
- 在初始化参数之后,我们的任务是更新这些参数,直到这些参数足够拟合我们的数据。
- 每次更新都需要计算损失函数关于模型参数的梯度。有了这个梯度,我们就可以向减小损失的方向更新每个参数。
- 我们使用自动微分来计算梯度。
定义模型
- 接下来,我们必须定义模型,将模型的输入和参数同模型的输出关联起来。所谓模型,就是将从输入通过与参数的元素得出结果的函数用程序表示出来。
- 要计算线性模型的输出,我们只需计算输入特征和模型权重的矩阵-向量乘法后加上偏移量。注意,上面的是一个向量,而是一个标量。通过广播机制,当我们用一个向量加一个标量时,标量会被加到向量的每个分量上。
def linreg(X, w, b):
"""线性回归模型。"""
return tf.matmul(X, w) + b定义损失函数
- 因为要更新模型。需要计算损失函数的梯度,所以我们应该先定义损失函数。所谓损失函数就是计算通过模型得到的输出与实际的输出(标签值)之间的偏差程度。损失函数实质是以模型参数为自变量,误差值为因变量的函数,因为预测值中含有的变量就是模型参数。
- 这里我们使用平方损失函数。
- 在实现中,我们需要将真实值
y的形状转换为和预测值y_hat的形状相同。
def squared_loss(y_hat, y):
"""平方损失函数"""
return (y_hat - tf.reshape(y, y_hat.shape)) ** 2 / 2定义优化算法
- 在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度(即损失函数关于模型参数的导数)。接下来,朝着减少损失的方向更新我们的参数。梯度下降解析
- 下面的函数实现小批量随机梯度下降更新。该函数接受模型参数集合、学习速率和批量大小作为输入。每一步更新的大小由学习速率
lr决定,学习率乘以导数就是沿梯度方向变化的幅度,模型参数减去这个幅度(步长)就实现了沿梯度下降方向的参数更新。梯度下降与学习率解析 - 因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(
batch_size)来归一化(就是除一下)步长,这样步长大小就不会取决于我们对批量大小的选择。(为什么需要归一化?) - python zip函数解析
# params是元素类型为tf.Varible的列表,grads使参数对应的损失函数导数,lr是学习率
def sgd(params, grads, lr, batch_size):
"""小批量随机梯度下降。"""
for param, grad in zip(params, grads): # zip函数将可迭代对象打包成一个个元组用于遍历
#tensorflow的assign_sub函数能够将param减去括号中参数的值再赋给param,实现更新参数
param.assign_sub(lr*grad/batch_size) 训练
- 现在我们已经准备好了模型训练所有需要的要素,可以实现主要的[训练过程]部分了。在整个深度学习的职业生涯中,会一遍又一遍地看到几乎相同的训练过程。
- 在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。计算完损失后,我们开始反向传播,存储每个参数的梯度。最后,我们调用优化算法
sgd来更新模型参数。
概括一下,我们将执行以下循环:
- 初始化参数
- 重复,直到完成
- 计算梯度
- 更新参数
- 在每个**迭代周期(epoch)**中,我们使用
data_iter函数遍历整个数据集,并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设为3和0.03。设置超参数很棘手,需要通过反复试验进行调整。(每个迭代周期都要使用完整个数据集,通过多次重复来找到最佳参数)。 - 注:tensorflow自动求导解析
lr = 0.03 #学习率
num_epochs = 3 #迭代周期
net = linreg #线性回归模型函数
loss = squared_loss #平方损失函数for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
with tf.GradientTape() as g: # 使用tensorflow的自动求导
l = loss(net(X, w, b), y) # `X`和`y`的小批量损失
# 计算l(损失函数)关于[`w`, `b`]的梯度
dw, db = g.gradient(l, [w, b])
# 使用参数的梯度更新参数
sgd([w, b], [dw, db], lr, batch_size)
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(tf.reduce_mean(train_l)):f}')epoch 1, loss 0.031377
epoch 2, loss 0.000106
epoch 3, loss 0.000048
因为我们使用的是自己合成的数据集,所以我们知道真正的参数是什么。
因此,我们可以通过[比较真实参数和通过训练学到的参数来评估训练的成功程度]。事实上,真实参数和通过训练学到的参数确实非常接近。
print(f'w的估计误差: {true_w - tf.reshape(w, true_w.shape)}')
print(f'b的估计误差: {true_b - b}')w的估计误差: [-0.00037241 -0.0001893 ]
b的估计误差: [0.00096989]
- 注意,我们不应该想当然地认为我们能够完美地恢复参数。在机器学习中,我们通常不太关心恢复真正的参数,而更关心那些能高度准确预测的参数。幸运的是,即使是在复杂的优化问题上,随机梯度下降通常也能找到非常好的解。其中一个原因是,在深度网络中存在许多参数组合能够实现高度精确的预测。
线性回归的简洁实现
- 通过深度学习框架可以自动化实现基于梯度的学习算法中重复性的工作。
- 在从零开始的实现中,我们只依赖了:(1)通过张量来进行数据存储和线性代数;(2)通过自动微分来计算梯度。实际上,由于数据迭代器、损失函数、优化器和神经网络层很常用,现代深度学习库也为我们实现了这些组件。
- 接下来,我们将通过使用深度学习框架来简洁地实现线性回归模型。
生成数据集
- 我们首先[生成数据集]。
import numpy as np
import tensorflow as tf
#根据数据集以及线性模型得出对应的y值向量
def synthetic_data(w, b, num_examples): # w为线性模型参数,b为偏移量,num_examples是数据集数据数量
"""生成 y = Xw + b + 噪声。"""
X = tf.zeros((num_examples, w.shape[0])) # 生成和w的列数一样,行数为num_examples的,值全为0矩阵
X += tf.random.normal(shape=X.shape) # 用标准正态分布的数值为X矩阵的每个元素赋值
# 将w转换为2行1列(-1代表自动推断此处应该填的维数)的矩阵与X矩阵相乘再加上偏移量计算y
y = tf.matmul(X, tf.reshape(w, (-1, 1))) + b
y += tf.random.normal(shape=y.shape, stddev=0.01) # 给y的值加上服从正态分布的误差
y = tf.reshape(y, (-1, 1)) # 将y转换为1列的矩阵
return X, ytrue_w = tf.constant([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)读取数据集
- 我们可以[调用框架中现有的API来读取数据]。我们将
features和labels作为API的参数传递,并在实例化数据迭代器对象时指定batch_size。此外,布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个TensorFlow数据迭代器。"""
# 使用tensorflow的API来读取特征值向量和标签向量生成数据集
dataset = tf.data.Dataset.from_tensor_slices(data_arrays)
if is_train:
dataset = dataset.shuffle(buffer_size=1000) # 打乱数据
dataset = dataset.batch(batch_size) # 得到批量随机数据迭代器
return datasetbatch_size = 10
data_iter = load_array((features, labels), batch_size) data_iter是一个小批量样本迭代器(可以用于for…Iin 循环遍历)。为了验证是否正常工作,让我们读取并打印第一个小批量样本。- 我们使用
iter构造Python迭代器,并使用next从迭代器中获取第一项。
next(iter(data_iter))(<tf.Tensor: shape=(10, 2), dtype=float32, numpy=
array([[-1.0550611 , -0.82872546],
[-0.28267154, -0.25637326],
[-0.5144283 , 0.44031686],
[-0.5526093 , -0.9219198 ],
[-0.1690998 , 0.75760716],
[-0.9019597 , -1.2707379 ],
[-1.4669428 , 1.035699 ],
[ 0.7166598 , -0.9520578 ],
[ 1.7674623 , 0.872534 ],
[-0.48834816, 0.7471352 ]], dtype=float32)>,
<tf.Tensor: shape=(10, 1), dtype=float32, numpy=
array([[ 4.9053 ],
[ 4.495085 ],
[ 1.6844876 ],
[ 6.2230234 ],
[ 1.2832037 ],
[ 6.728463 ],
[-2.2450213 ],
[ 8.868936 ],
[ 4.7641516 ],
[ 0.68498605]], dtype=float32)>)
定义模型
-
当我们从零实现线性回归时,我们明确定义了模型参数变量,并编写了计算的代码,这样通过基本的线性代数运算得到输出。但是,如果模型变得更加复杂,而且当你几乎每天都需要实现模型时,你会想简化这个过程。
-
对于标准操作,我们可以[使用框架的预定义好的层]。这使我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。即,不用关心模型应该怎么表达,框架会自动根据数据来拟合一个模型函数,并且最后得到它的最佳参数。
-
我们首先定义一个模型变量
net,它是一个Sequential类的实例。Sequential类为串联在一起的多个层定义了一个容器。当给定输入数据,Sequential实例将数据传入到第一层,然后将第一层的输出作为第二层的输入,依此类推。在下面的例子中,我们的模型只包含一个层,因此实际上不需要Sequential。但是由于以后几乎所有的模型都是多层的,在这里使用Sequential会让你熟悉标准的流水线。 -
全连接层(fully-connected layer):它的每一个输入都通过矩阵-向量乘法连接到它的每个输出。因为我们的数据实际是满足线性模型的,即标签值是通过自变量的一个线性函数运算得到,自变量与因变量(输入与输出)之间是一一对应的关系,所以满足全连接。
-
在Keras中,全连接层在
Dense类中定义。由于我们只想得到一个标量输出,所以我们将该数字设置为1。 -
值得注意的是,为了方便使用,Keras不要求我们为每个层指定输入形状(即不知道数据到底有多少)。所以在这里,我们不需要告诉Keras有多少输入进入这一层。当我们第一次尝试通过我们的模型传递数据时,例如,当后面执行
net(X)时,Keras会自动推断每个层输入的形状。我们稍后将详细介绍这种工作机制。
# `keras` 是TensorFlow的高级API
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(1))初始化模型参数
-
在使用
net之前,我们需要初始化模型参数。如在线性回归模型中的权重和偏置。 -
深度学习框架通常有预定义的方法来初始化参数。在这里,我们指定每个权重参数应该从均值为0、标准差为0.01的正态分布中随机采样,偏置参数将默认初始化为零。
-
TensorFlow中的
initializers模块提供了多种模型参数初始化方法。在Keras中最简单的指定初始化方法是在创建层时指定kernel_initializer。在这里,我们重新创建了net。
initializer = tf.initializers.RandomNormal(stddev=0.01)
net = tf.keras.Sequential()
net.add(tf.keras.layers.Dense(1, kernel_initializer=initializer))- 初始化的推迟执行:上面的代码可能看起来很简单,但是你应该注意到这里的一个细节:我们正在为网络初始化参数,而Keras还不知道输入将有多少维!网络的输入可能有2维,也可能有2000维。Keras让我们避免了这个问题,在后端执行时,初始化实际上是推迟(deferred)执行的。只有在我们第一次尝试通过网络传递数据时才会进行真正的初始化。只是要记住,因为参数还没有初始化,所以我们不能访问或操作它们。
定义损失函数
- 计算均方误差使用的是
MeanSquaredError类,也称为平方范数。默认情况下,它返回所有样本损失的平均值。框架帮我们定义好了各种损失函数。
loss = tf.keras.losses.MeanSquaredError()定义优化算法
- 小批量随机梯度下降算法是一种优化神经网络的标准工具,Keras在
optimizers模块中实现了该算法的许多变种。小批量随机梯度下降只需要设置learning_rate值(学习率),这里设置为0.03。框架将我们更新参数的函数也内置定义好了。
trainer = tf.keras.optimizers.SGD(learning_rate=0.03)训练
- 通过深度学习框架的高级API来实现我们的模型只需要相对较少的代码。我们不必单独分配参数、不必定义我们的损失函数,也不必手动实现小批量随机梯度下降。
- 在每个迭代周期里,我们将完整遍历一次数据集(
train_data),不停地从中获取一个小批量的输入和相应的标签。对于每一个小批量,我们会进行以下步骤:- 通过调用
net(X)生成预测并计算损失l(正向传播)。 - 通过进行反向传播来计算梯度。
- 通过调用优化器来更新模型参数。
- 通过调用
- 为了更好的衡量训练效果,我们计算每个迭代周期后的损失,并打印它来监控训练过程。
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter: # 迭代获取小批量数据样本
with tf.GradientTape() as tape:
l = loss(net(X, training=True), y) # 计算损失
grads = tape.gradient(l, net.trainable_variables) # 计算损失函数关于训练的参数的导数
trainer.apply_gradients(zip(grads, net.trainable_variables)) # 根据计算的导数更新参数
l = loss(net(features), labels) # 本次迭代结束后,利用更新后的参数来计算损失,用于监控训练进展
print(f'epoch {epoch + 1}, loss {l:f}')epoch 1, loss 0.000191
epoch 2, loss 0.000098
epoch 3, loss 0.000097
- 下面我们[比较生成数据集的真实参数和通过有限数据训练获得的模型参数]。
- 要访问参数,我们首先从
net访问所需的层,然后读取该层的权重和偏置。
w = net.get_weights()[0]
print('w的估计误差:', true_w - tf.reshape(w, true_w.shape))
b = net.get_weights()[1]
print('b的估计误差:', true_b - b)w的估计误差: tf.Tensor([-0.00038457 -0.00020194], shape=(2,), dtype=float32)
b的估计误差: [-0.00032425]
- 可以看出,训练得出的参数和实际参数非常接近。