余弦相似度简述
- 余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
- 两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合,此时说明两个向量完全一致。
- 引入余弦相似度,来判断文本相似程度,将词语是否出现变更为词语在文本中的权重。
- 计算公式:
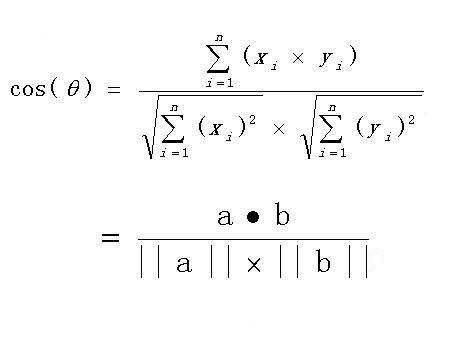
实现利用余弦相似度计算句子相似度
Github地址
import numpy as np
# 创建语料库
corpus = ['this is the first document',
'this is the second second document',
'and the third one',
'is this the first document']
# 创建一个空列表与words_list = []等效
words_list = list()
# len(corpus)计算语料库容器的元素数量,即有4个字符串
# range生成一个连续的链表,如此处len(corpus)=4,就生成从0到3的连续链表,实质是使计数变量i从0到3递增变化
for i in range(len(corpus)):
# spilt函数用指定的分隔符将字符串拆分为一个列表,将这个列表作为一个元素存入words_list列表
words_list.append(corpus[i].split(' '))
print(words_list)
[['this', 'is', 'the', 'first', 'document'], ['this', 'is', 'the', 'second', 'second', 'document'], ['and', 'the', 'third', 'one'], ['is', 'this', 'the', 'first', 'document']]
# 获取文本中的所有词(不消除重复)
temp = list()
for words in words_list:
temp += words
# 通过set集合的唯一性去除重复的词,并转换为列表
key_words = list(set(temp))
print(key_words)
['is', 'third', 'this', 'and', 'one', 'the', 'document', 'first', 'second']
word_vector1 = np.zeros(len(key_words))
word_vector2 = np.zeros(len(key_words))
word_vector3 = np.zeros(len(key_words))
word_vector4 = np.zeros(len(key_words))
print(word_vector1)
[0. 0. 0. 0. 0. 0. 0. 0. 0.]
# 创建一个列表存储所有的向量
vectors = list()
vectors.append(word_vector1)
vectors.append(word_vector2)
vectors.append(word_vector3)
vectors.append(word_vector4)
print(vectors)
[array([0., 0., 0., 0., 0., 0., 0., 0., 0.]), array([0., 0., 0., 0., 0., 0., 0., 0., 0.]), array([0., 0., 0., 0., 0., 0., 0., 0., 0.]), array([0., 0., 0., 0., 0., 0., 0., 0., 0.])]
- 遍历关键词列表和每个句子的单词列表,确定每个向量每个位置的值
for i in range(len(key_words)):
for j in range(len(vectors)):
for word in words_list[j]:
if key_words[i] == word:
vectors[j][i] += 1
print(key_words)
for vector in vectors:
print(vector)
['is', 'third', 'this', 'and', 'one', 'the', 'document', 'first', 'second']
[1. 0. 1. 0. 0. 1. 1. 1. 0.]
[1. 0. 1. 0. 0. 1. 1. 0. 2.]
[0. 1. 0. 1. 1. 1. 0. 0. 0.]
[1. 0. 1. 0. 0. 1. 1. 1. 0.]
cosine12 = float( (np.sum(vectors[0] * vectors[1])) / (np.linalg.norm(vectors[0]) * np.linalg.norm(vectors[1])))
print(cosine12)
0.6324555320336759
cosine13 = float( (np.sum(vectors[0] * vectors[2])) / (np.linalg.norm(vectors[0]) * np.linalg.norm(vectors[2])))
print(cosine13)
0.22360679774997896
cosine14 = float( (np.sum(vectors[0] * vectors[3])) / (np.linalg.norm(vectors[0]) * np.linalg.norm(vectors[3])))
print(cosine14)
0.9999999999999998
- 根据余弦值的大小得出结论(值越大,相似度越高)句子3和句子1相似度最高,句子2和句子1相似度最低。而人为判断也是这样。