第三章 限定性线性表-栈与队列
栈
定义
- 栈与队列都是特殊的线性表,是操作受限的线性表,称为限定性线性表。
- 特点:先进后出(FILO:first in last out)或后进先出(LIFO:last in first out)

- 线性表可以在任意位置插入、删除,而栈只允许在栈顶进行插入或者删除操作,故称为操作受限。
- 典例:
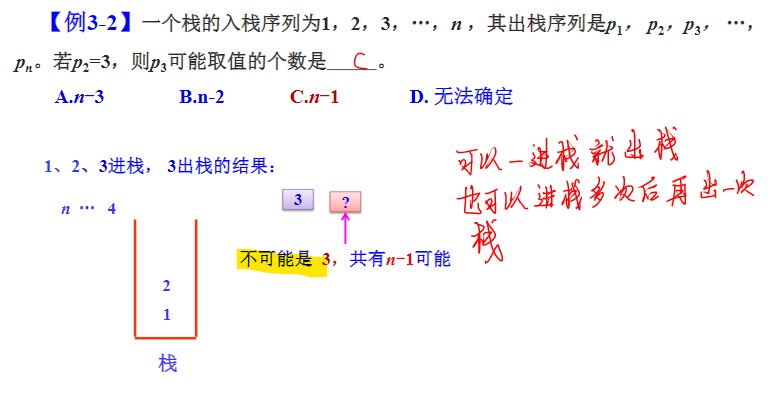
- 栈的几种基本运算

栈的两种存储结构
- 顺序存储结构:
- 优势:存取时定位很方便
- 劣势:顺序栈需要一个事先固定的长度,可能会存在空间浪费和不足(栈满)的情况
- 链式存取结构:
- 优势:栈的长度无限制
- 劣势:存取定位不方便,且需要每个元素都有一个指针域,增加了内存开销。
- 总结:当栈的使用过程中元素数量变化范围不可定,有时很大,有时很小,那么使用链栈;反之,如果变化范围在可控范围内,则使用顺序栈。
栈的顺序存储结构
栈的顺序存储结构的定义
-
结点类型:

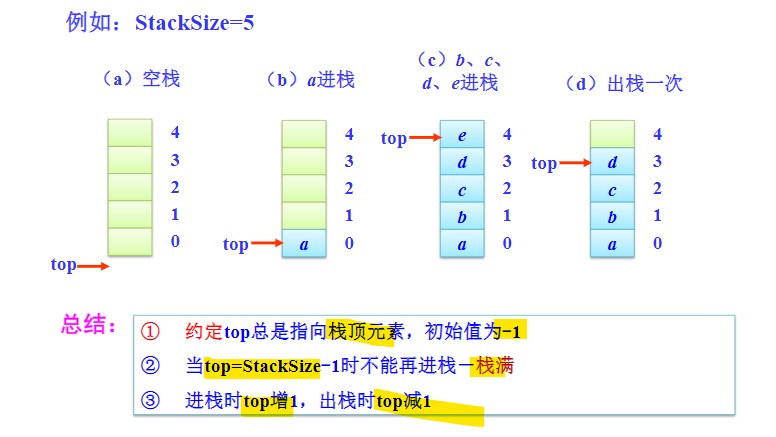
- 用数组存储结点数据;
- 需要设置一个栈顶指针,但其实top的实际值不是指针,而只是栈顶元素的数组下标,初始值为-1,表示栈空。
-
基本原理示意:
- top指针始终指向栈顶元素,且初始值为-1。
-
顺序栈四要素:
- 栈空条件:
top == -1 - 栈满条件:
top == StackSize - 1 - 进栈操作:
top++,然后将元素赋给对应数组元素:data[top] = e - 退栈操作:
top--,然后返回对应元素值。
- 栈空条件:
栈在顺序栈中实现的基本运算
初始化栈(创建)
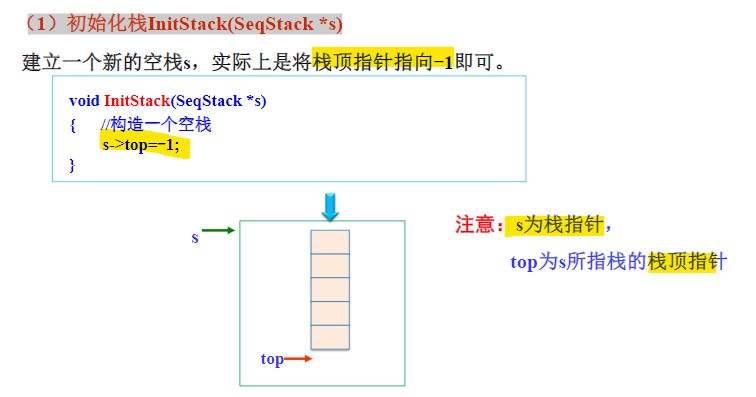
top = -1即可创建空栈;- 注意栈指针与栈顶“指针”的区别。
判断栈是否为空

- 判空条件
top == -1 - 直接返回判等式的真假值即可作为栈是否为空的真假值。
进栈

- 先要判断栈是否已满;
- 栈顶指针
top++,再放对应元素即可。
出栈
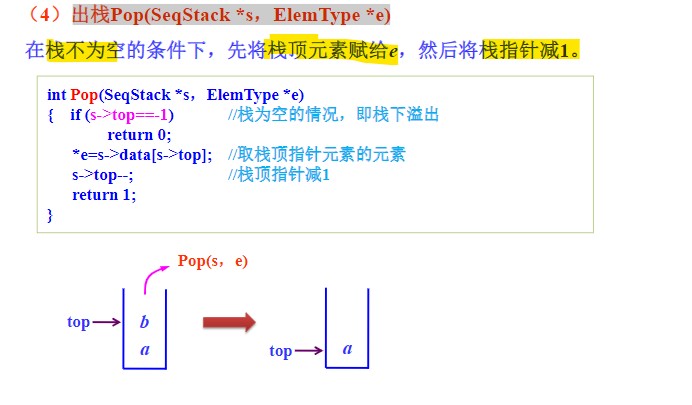
- 先要判断栈是否为空;
- 栈顶指针
top--即可。 - 若单纯取栈顶元素,去掉
top--即可,但仍要判断栈是否为空。 - 利用进栈顺序与出栈顺序刚好相反可以用来判断一个字符串是否是对称串。

两栈共享技术
- 适用于两个相同类型的栈。
- 目的是节约存储空间,特别是解决一个栈已满,而另一个栈剩余空间还很多的情况。

- 用一个数组来储存两个栈,数组的头尾两端分别对应两个栈的栈底,增加元素则是两个top指针在向中间靠拢。
- 用一个小数组来存储两个栈的栈顶指针。
两栈共享的初始化
void InitStack(DqStack *S)
{
S->top[0] = -1;
S->top[1] = M;//数组末端再外面一格,表示该栈为空
}- 注意靠近末端栈的栈顶指针是反着的。
两栈共享的进栈
int Push(DqStack *S, StackEkementType x, int i)
{
if(S->top[0] + 1 == S->top[1])
return (FALSE);
switch(i)
{
case 0:
S->top[0]++;
S->Stack[S->top[0]] = x;
break;
case 1:
S->top[1]--;
S->Stack[S->top[1]] = x;
break;
default:
return (FALSE);
}
return (TRUE)
}- 先要判断栈是否已满:
S->top[0] + 1 == S->top[1],即两个栈顶指针是否已经抵到一起,即它们之间只相差1。 - 还需要判断新元素是进入哪个栈;
- 注意两个栈的栈顶指针向前移动的方式是相反的,一个是加,一个是减。
两栈共享的出栈

- 在判断好是哪个栈要出栈的基础上,还要判断该栈是否为空。
- 出栈只需对应栈顶指针向对应的栈底方向减一位即可。
栈的链式存储结构
- 使用链表存储的栈称为链栈。
- 基本原理:
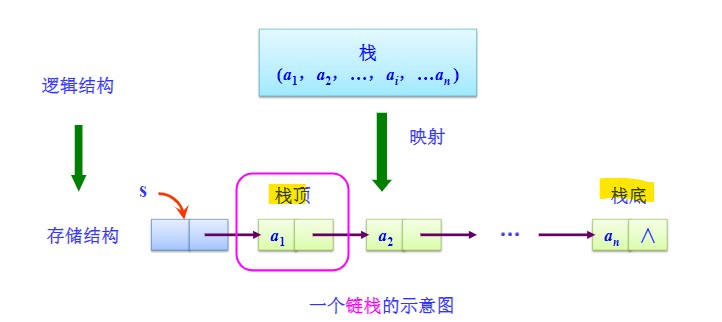
- 带头结点s.
- 栈顶为头结点后,栈底为链表链尾。
- 结点定义:
- 链表4要素:
- 栈空条件:
s->next == NULL - 栈满条件:链栈是无限的,不会满溢。
- 进栈操作:头插法。
- 退栈操作:取出头结点后第一个结点,并释放其空间,并将头结点与下一个结点连接好。
- 栈空条件:
链栈的基本运算算法
初始化栈
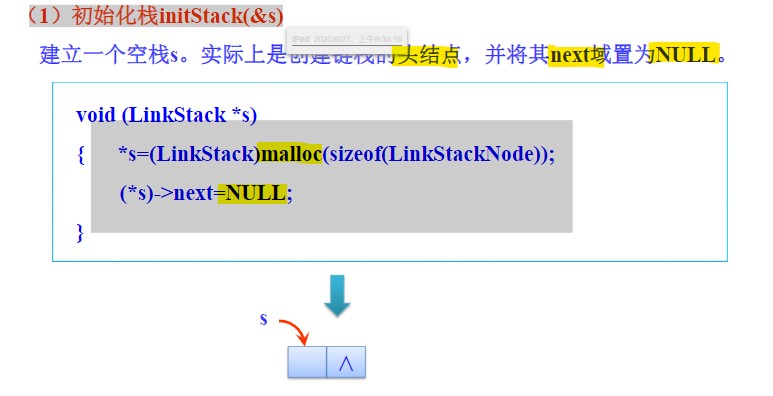
- 创建头结点(为其分配空间),并将其指针域置为NULL。
销毁栈
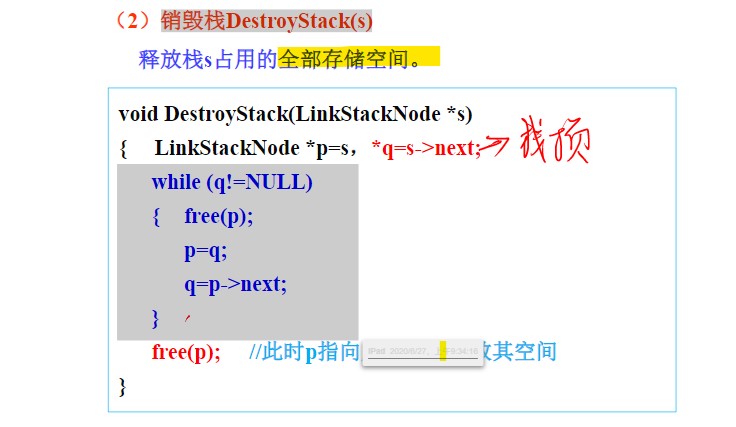
- 设立两个移动的指针,一个指向当前被释放的结点,一个指向其下一个结点,不断扫描下去。
- 最后p指针会指向栈底结点,不要忘了将其释放。
判断链栈是否为空
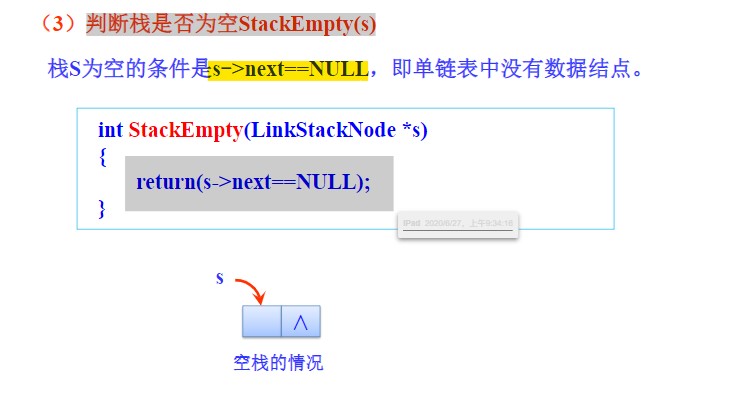
- 链栈为空的条件是头结点的指针域为空,即
s->next == NULL
进栈
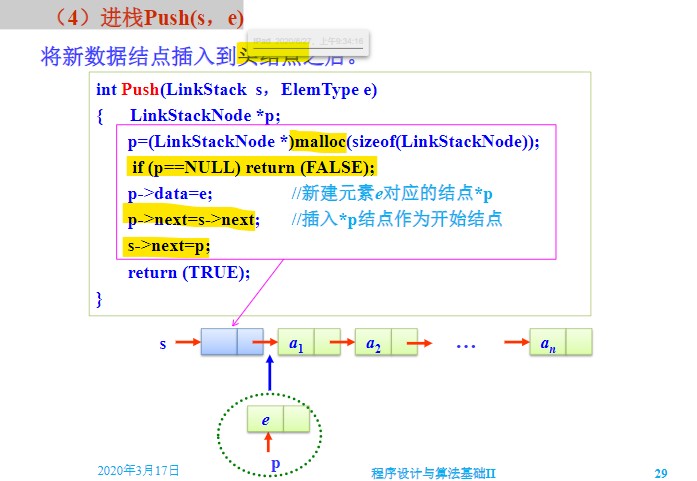
- 每次为新结点分配空间都要判断分配是否成功。
- 头插法进栈
出栈

- 先要判断栈是否为空
p == NULL - 然后将头结点的指针域设为当前结点的下一个结点即可
- 若是单纯取出元素,则仅仅去掉改指针,释放空间的一步即可。
栈的经典题目
1.一种括号配对
- 基本思路:

- 只将左括号进栈,遇到一个右括号则出栈一个左括号与其相匹配;
- 成功匹配的条件是,栈为空,且所有括号已扫描完。
- 算法实现:

- 先要创建一个空链栈;
- 最后若一直匹配完了,还要判断栈是否为空来确定是否匹配成功。
队列
定义
- 队列简称队,是一种运算受限的线性表;
- 队列只允许在一端进行插入操作,而在另一端进行删除操作。允许插入的一端称为队尾,允许删除的一端称为队头。
- 特点:先进先出(FIFO:first in first out),与栈刚好想反。

- 队列的基本运算

队列的存储结构
- 链式存储结构
- 不带头结点但头结点后面设置一个空结点的链队
- 不带头结点且头结点后直接就是第一个数据结点的链队
- 顺序存储结构
- 单向顺序队列
- 环形顺序队列
队列的链式存储结构
-
带头结点没有空结点的链队
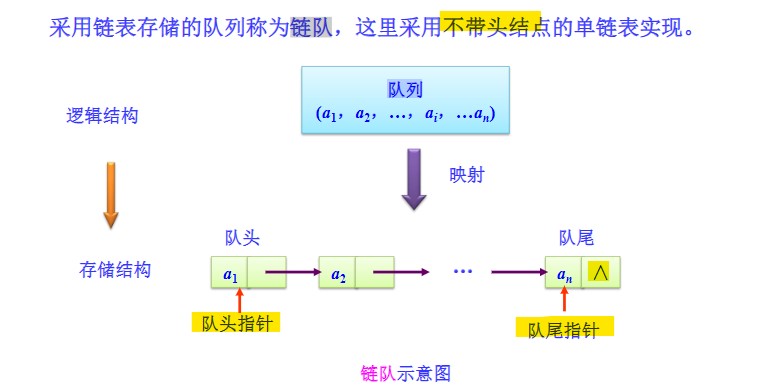
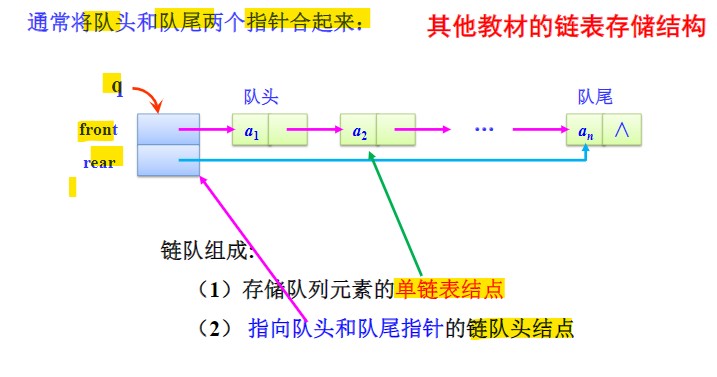
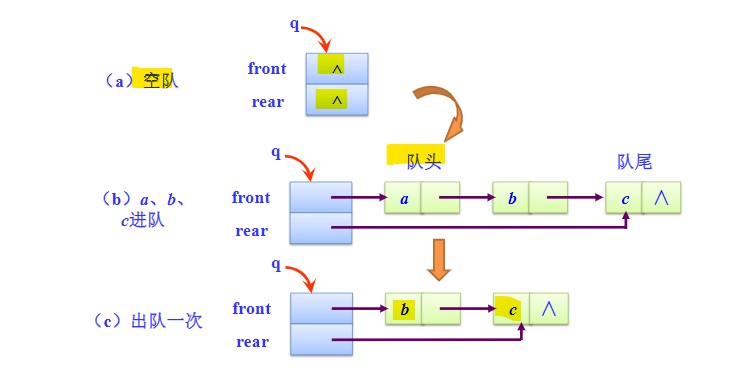

- 设置队头和队尾指针,队头指针始终指向第一个数据结点,队尾指针始终指向最后一个数据结点,队列遵循尾进头出的规则。
- 设置一个小数组(或者结构)来储存两个指针,其实相当于原来的头结点的升级版。
- 链队4要素:
- 空队的条件:
front == rear && front == NULL - 链队是不会出现队满的情况的。
- 进队操作:将新结点尾插法插入队尾后
- 出队操作:删除第一个数据结点。
- 空队的条件:
-
带头结点有空结点的链队
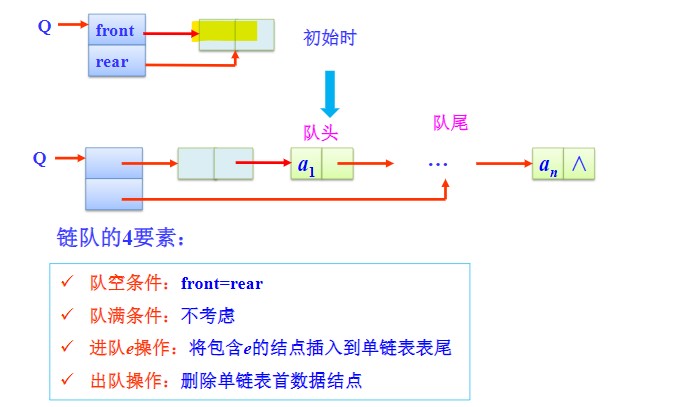
- 链队4要素
- 队空条件:
front == rear,两个指针开始时都指向设置的第一个空结点; - 不会出现队满的情况;
- 进队操作:尾插法;
- 出队操作:删除第一个非空的数据结点
- 队空条件:
- 所以呢?空结点设来有啥用?
- front指针域永远不用变动,每次不管什么操作,最多改变rear指针,而front指针是永远指向那个空结点的。
- 链队4要素
-
不带头结点只有尾指针的循环链表队列

- 链队4要素
- 队空条件:
rear == NULL - 队满条件:无限。
- 进队操作:将新结点插入队尾;
- 出队操作:删除单链表首结点。
- 队空条件:
- 初始化:
rear = NULL - 判空:
rear == NULL - 进队:(新结点为p)
- 原队列为空:
p->next = p; rear = p - 原队列不为空:
p->next = rear->next; rear->next =p; rear = p
- 原队列为空:
- 出队:
- 原队中只有一个结点:
free(rear); rear = NULL - 原队中有两个及以上结点:
q = rear->next; rear->next = q->next; free(q)
- 原队中只有一个结点:
- 链队4要素
带头结点设空结点链队的基本运算
初始化队列

- 传进来的参数是指向新版头结点的指针;
- 分配一个空的数据结点的空间,让front 和rear指针都指向它,而把它的next域置为NULL。
清空队列
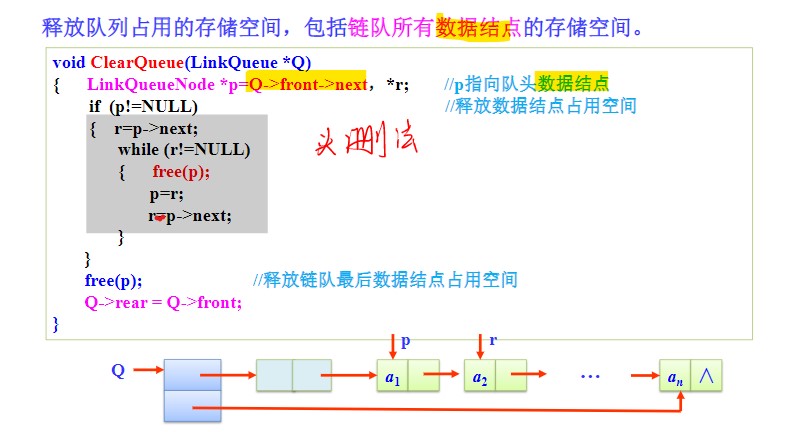
- 设置两个移动指针,一个指向当前第一个非空数据结点,另一个指向其下一结点;
- 每次释放掉第一个非空数据结点,然后顺序移动指针,扫描队列;
- 结束的条件是当前的第一个非空结点的next域为空,即
r != NULL或p->next != NULL - 最后释放掉最后一个结点,记得将rear指针域指向空结点。
判断队列是否为空
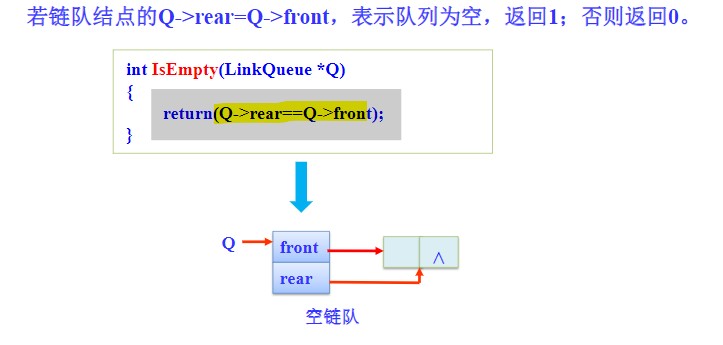
- 只需判断front 和rear指针是否相等即可,因为front指针永远指向那个空结点。
进队

- 为新结点分配一个空间(记得看分配是否成功;
- 将新结点接到尾结点后,并移动rear指针。
出队
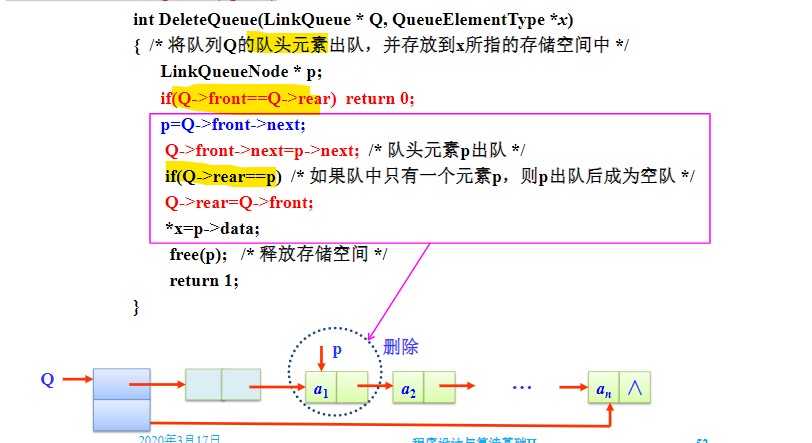
- 先要判断队列是否为空;
- 然后设置一个指针指向队头元素,以便读出队头元素的数据,以及将空结点的指针域移到队头元素的下一个结点(若没有下一结点,则自然设为了NULL)
- 还要注意队头元素是否同时是队尾元素,若是,则需要先将rear指针改为指向空结点,再释放该结点。
队列的顺序表存储结构
- 顺序队列的两种存储方式
-
顺序队列(普通的单向队列):
- 劣势:假溢出问题:当我们认为队列已满不能进队时,其实数组里还有多余的空位置。
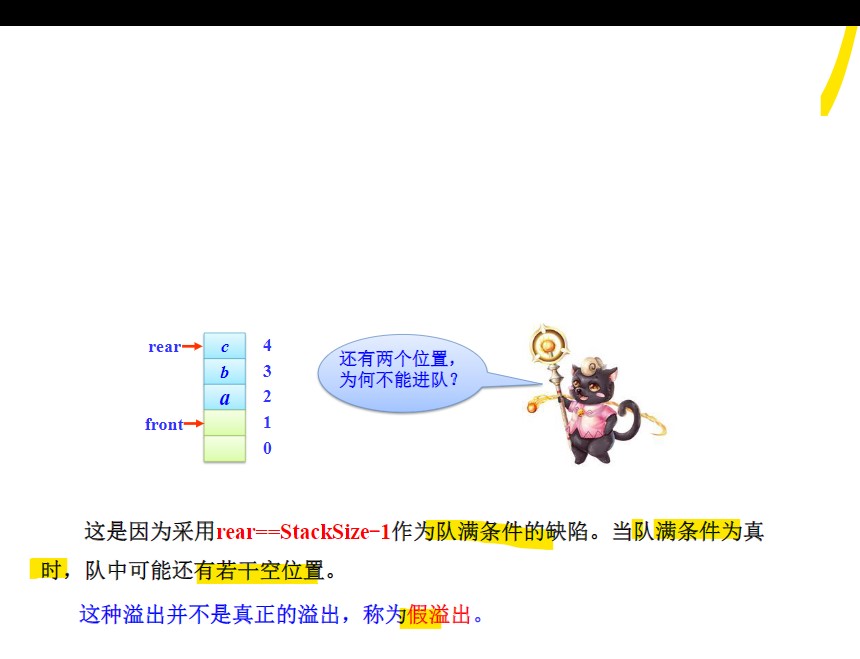
- 劣势:假溢出问题:当我们认为队列已满不能进队时,其实数组里还有多余的空位置。
-
循环队列
-
1.单向顺序队
定义
-
结点定义
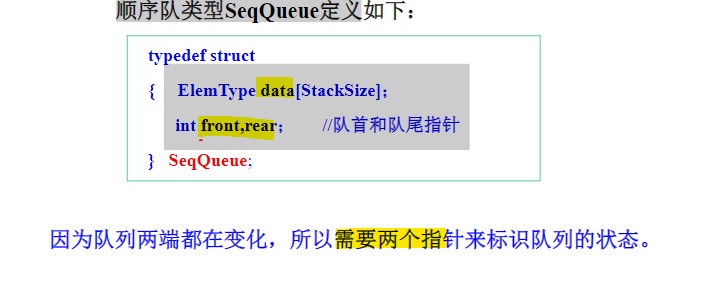
- 用数组存储;
- 设置指向队头和队尾的“模拟指针”,标明数组的头尾下标,以达到类似指针的指向队头和队尾的效果;
-
基本原理:
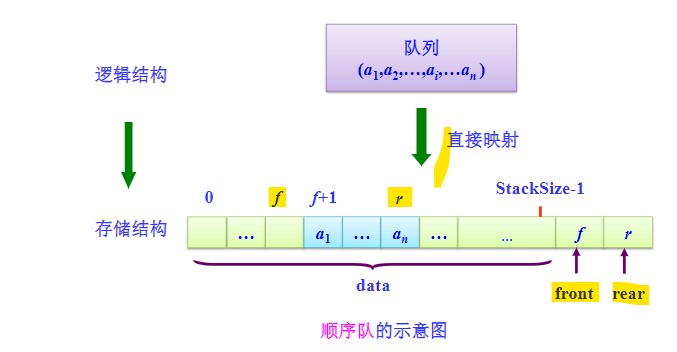

- rear指针始终指向队尾元素,且每次增加一个元素,rear指针加一,数组新的位置用以放新元素;
- front指针始终指向队头,且front指向下是始终没有数据元素的;每当元素出队,front则加一前移一位,所以队列与栈不同,用数组表示队列,经常会出现元素在整个数组的中间的情况,前不搭头,后不着尾。
-
单向顺序队4要素:
- 队空条件:
front == rear - 队满条件:
rear == StackSize - 1 - 进队操作:
rear++; data[rear] = e //e 为新加数据元素 - 出队操作:
front++;
- 队空条件:
单向顺序队的基本运算
初始化

- 整个顺序队其实是一个结构体,这个结构体中含有一个数组和两个充当“指针”的整数(实际是记录下标)
- 为结构体分配好空间后,再将front和rear都置为-1,表示指向整个队列之前,此时队列为空。
销毁队列

- 不用像链队一样需要将每一个结点空间释放(因为本来就只有一个结点,实际用来储存的是数组);
- 只需要将front和rear都置为-1,形式上表示此队列为空即可,数组中实际留有的数据,在下一次使用队列便覆盖了,没有影响。
判断栈是否为空

- 只需判断front和rear是否相等即可。
进队
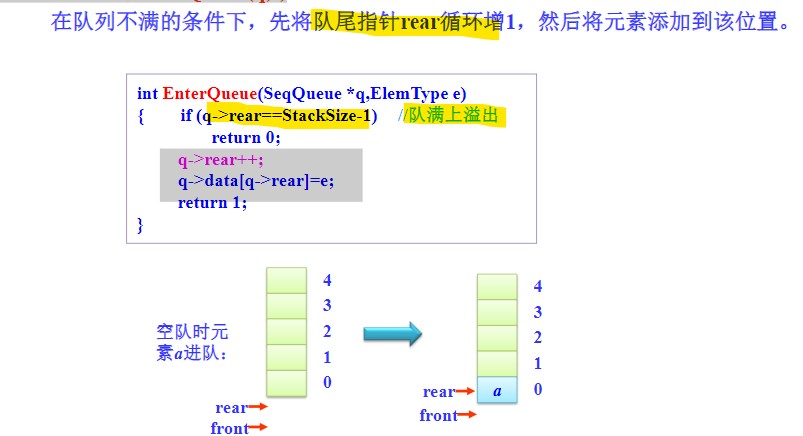
- 注意:先要判断队满与否;
- 然后rear进一位,将数据赋入对应位置即可。
出队

- 先要判断队是否为空:
q->front == q->rear - 然后将front前移一位(+1)即可。
2. 环形队列
定义
- 基本原理
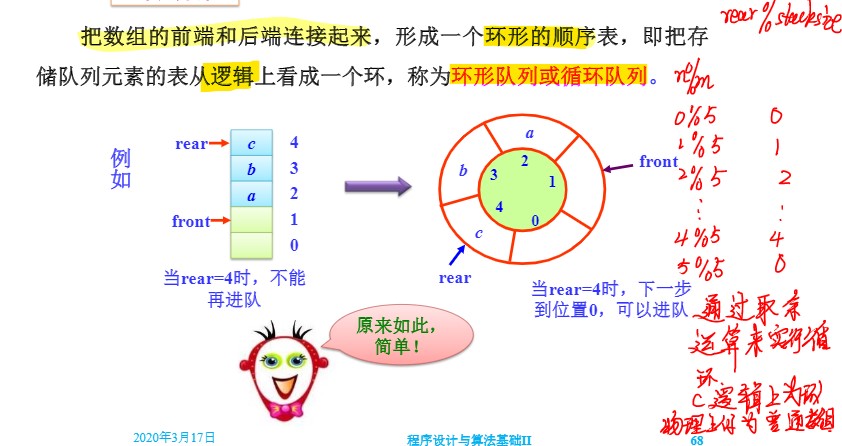

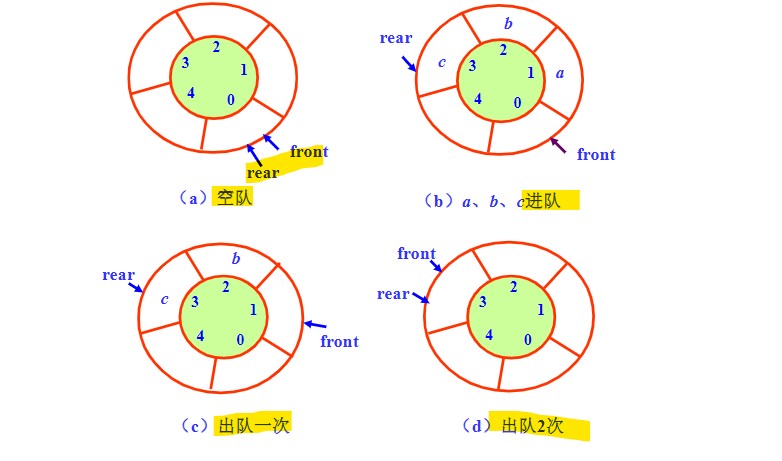
- 逻辑上看成一个环形的队列,但实际用来存储的还是一个普通的数组。
- 利用取余计算结果的循环往复性,在逻辑上实现一个环形;
- 约定当rear==front的时候队列为空,可以理解为由于不断有元素出队,front不断前移,当front最终于rear相等的时候说明两者之间的元素已经全部出队列了,此时队列为空。
- 如果不对队满的条件加以限制,则当队列真正满的时候,rear 还是与front相等。所以约定
(rear + 1) % StackSize == front时为队满条件,即rear还需再加一位才与front相等,也可以理解为此时由于不断有元素进队,rear在一直向前加,马上就要与front相“撞”,我们牺牲一个位置(即rear在即将与front相撞前指向的位置)来保证与队空条件的区分。
- 环形队列的4要素;
- 队空条件:
front == rear - 队满条件:
(rear + 1) % StackSize == front - 进队操作:
rear = (rear + 1) % StackSize,若不好理解,就直接理解rear最开始小于StackSize的时候,此时取余元素没有效果,就相当于简单的加1。因为取余运算的效果就是不管rear执行过多少次加法来移动,始终都被局限于StackSize的范围内重复“绕圈”。 - 出队操作:
front = (front + 1) % StackSize
- 队空条件:
环形队列的基本运算
初始化

- 实际只要保证front与rear相等即可,为不为0并不重要。
入队

- 先要判断队列是否已满;
- 之后再将rear指针前移一位。
出队

- 先要判断队列是否为空;
- 之后只要将front指针向前移一位即可。
环形队列的简化
-
根据头指针和队列中的元素个数可以计算出队尾指针,因此可以将队尾指针rear去掉。
-
计算队列中的元素个数和指针的公式:

- 公式中的取余运算时咋推出来的?
-
结点定义:
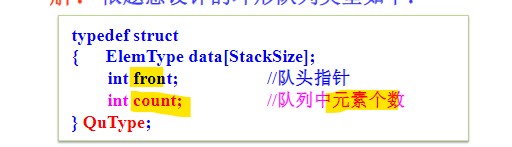
- 去掉尾指针rear增加元素数量count
-
无尾指针环形队列的4要素
- 队空条件:count == 0;
- 队满条件:count == StackSize;
- 进队操作:先由count和front求出rear指针,再进行与普通环形队列同样的操作;
- 出队操作:同普通环形队列。