第九章 内排序
9.1 排序的概念
排序的定义
所谓排序,是整理表中的记录,使之按关键字递增(或递减)有序排列。
内排序与外排序
在排序过程中,若整个表都是放在内存中处理,排序时不涉及数据的内、外存交换,则称之为内排序;反之,若排序过程中要进行数据的内、外存交换,则称之为外排序。
内排序
内排序的分类
- 基于比较的排序算法
- 插入排序
- 交换排序
- 选择排序
- 归并排序
- 不基于比较的排序算法
- 基数排序
?->基于比较的内排序的时间复杂度
- 最好的平均时间复杂度:
- 最好情况是排序序列正序,此时时间复杂度:
内排序算法的稳定性
- 如果待排序的表中,存在有多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,则称这种排序方法是稳定的。
- 反之,若具有相同关键字的记录之间的相对次序发生变化,则称这种排序方法是不稳定的。
正序与反序
- 若待排序的表中元素已按关键字排好序,称此表中元素为正序;
- 反之,若待排序的表中元素的关键字顺序正好和排好序的顺序相反,称此表中元素为反序。
- 有一些排序算法与初始序列的正序或反序有关,另一些排序算法与初始序列的情况无关。
内排序数据的组织
待排序顺序表的数据元素类型定义:
typedef struct
{
KeyType key; //关键字项
InfoType data; //其它数据项
}RecType; // 排序的记录类型定义9.2 插入排序
概述
- 基本原理:将无序区的元素逐个插入有序区(局部有序)
- 分类:
- 直接插入排序
- 折半插入排序
- 希尔排序
1.直接插入排序
-
基本原理:插入排序通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入 ,如此重复,直至完成序列排序。
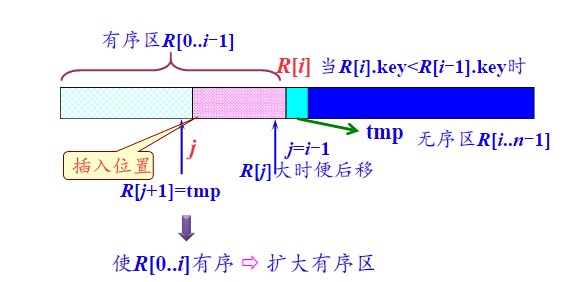
-
算法分析:
- 从序列第一个元素开始,该元素可以认为已经被排序(即有序区第一个元素)
- 取出下一个元素,设为待插入元素(即放入临时区:因为需要在有序区中插入一个元素,所以有序区得扩充一格,而临时区既能放置未找到位置的新入元素,又能为之后有序区元素的后移提供操作空间),在已经排序的元素序列中从后向前扫描,如果该元素(已排序)大于待插入元素,将该元素移到下一位置。
- 重复步骤2,直到找到已排序的元素小于或者等于待排序元素的位置,插入元素。
- 重复2,3步骤,完成排序。(得有两个循环嵌套)
-
实例演示:

- 默认序列的第一个元素12已经被排序
- 取下一元素 15,从后往前与已排序序列一次比较,15插入12 之后,已排序序列为[12,15]。
- 取下一元素9,重复2步骤,将9插12 之前,已排序序列为[9,12,15]。
- 循环上述操作,直至最后一个元素24,插入合适位置,完成排序。
-
直接插入排序代码(c)
void InsertSort(RecType R[],int n) { int i,j; RecType temp; for(i = 1; i < n; i++){ temp = R[i]; // 将取出的无序区元素放入临时区 j = i - 1; // 找到有序区最后一个元素 while(j >= 0 && R[j] > temp){ R[j + 1] = R[j]; j--; } //从后往前逐个扫描有序区元素,直到找到比新入元素小或者相等的元素,同时将比新入元素大的元素这个往后移一位 R[j] = temp; //将新入元素插入扫描找到的元素之后 } } -
性能分析
- 时间复杂度:
- 最好的情况(正序排列):比较次(每个元素只与自己前面的元素比一次,而第一个元素没有前面的元素),时间复杂度为
- 最坏的情况(反序排列):比较次(每个元素需与自己前面所有元素比一次),时间复杂度
- 平均时间复杂度:
- 空间复杂度:
- 只有一个临时元素,故空间复杂度为
- 算法稳定性:
- 直接插入排序是稳定的排序算法
- 时间复杂度: