Linux
一、操作系统简介
- 计算机是一台机器,它按照用户的要求接收信息、存储数据、处理数据,然后再将处理结果输出(文字、图片、音频、视频等)。计算机由硬件和软件组成。
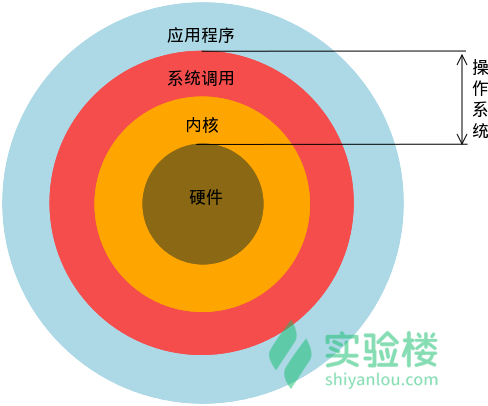
- 操作系统(Operating System,OS)是软件的一部分,它是硬件基础上的第一层软件,是硬件和其它软件沟通的桥梁(或者说接口、中间人、中介等)。
- 操作系统会控制其他程序运行,管理系统资源,提供最基本的计算功能,如管理及配置内存、决定系统资源供需的优先次序等,同时还提供一些基本的服务程序,例如:
- 文件系统:提供计算机存储信息的结构,信息存储在文件中,文件主要存储在计算机的内部硬盘里,在目录的分层结构中组织文件。文件系统为操作系统提供了组织管理数据的方式。
- 设备驱动程序:提供连接计算机的每个硬件设备的接口,设备驱动器使程序能够写入设备,而不需要了解执行每个硬件的细节。
- 用户接口:操作系统需要为用户提供一种运行程序和访问文件系统的方法。如常用的 Windows 图形界面,可以理解为一种用户与操作系统交互的方式;智能手机的 Android 或 iOS 系统,也是一种操作系统的交互方式。
- 系统服务程序: 当计算机启动时,会自启动许多系统服务程序,执行安装文件系统、启动网络服务、运行预定任务等操作。
概览:
二、Linux简介
Linux历史概述
Linux内核最初是由李纳斯•托瓦兹(Linus Torvalds)在赫尔辛基大学读书时出于个人爱好而编写的,当时他觉得教学用的迷你版UNIX操作系统Minix太难用了,于是决定自己开发一个操作系统。第1版本于1991年9月发布,当时仅有10000行代码。李纳斯•托瓦兹没有保留Linux源代码的版权,公开了代码,并邀请他人一起完善Linux。与Windows及其他有专利权的操作系统不同,Linux开放源代码,任何人都可以免费使用它。
Linux版本
- Linux的版本分为内核版本和发行版本。
- Linux有上百种不同的发行版,如基于社区开发的debian、archlinux,和基于商业开发的Red Hat Enterprise Linux、SUSE、Oracle Linux等。
Linux特性
开源性
大都为开源自由软件,用户可以修改定制和再发布,由于基本免费没有资金支持,部分软件质量和体验欠缺;由全球所有的 Linux 开发者和自由软件社区提供支持。
操作特性
兼具图形界面操作(需要使用带有桌面环境的发行版)和完全的命令行操作,可以只用键盘完成一切操作,新手入门较困难,需要一些学习和指导,一旦熟练之后效率极高。
多用户、多任务性
Linux支持多用户,各个用户对于自己的文件设备有自己特殊的权利,保证了各用户之间互不影响。多任务则是现在电脑最主要的一个特点,Linux可以使多个程序同时并独立地运行。
多平台性
Linux可以运行在多种硬件平台上,如具有x86、680x0、SPARC、Alpha等处理器的平台。此外Linux还是一种嵌入式操作系统,可以运行在掌上电脑、机顶盒或游戏机上。
可定制性
Linux系统是完全开放、免费的。正是由于开放性,它可以任意修改源代码,定制用户所需的系统,这是其他系统所不具备的。
选择Linux的原因
Linux的应用
-
服务器领域:
Linux作为企业级服务器的应用十分广泛,利用Linux系统可以为企业构架WWW服务器、数据库服务器、负载均衡服务器、邮件服务器、DNS服务器、代理服务器(透明网关)、路由器等。大型、超大型互联网企业(百度、新浪、淘宝等)都在使用Linux系统作为其服务器端的程序运行平台,全球及国内排名前十的网站使用的几乎都是Linux系统。 -
嵌入式领域:
在嵌入式应用的领域里,从因特网设备(路由器、交换机、防火墙、负载均衡器等)到专用的控制系统(自动售货机、手机、PDA、各种家用电器等),Linux操作系统都有很广阔的应用市场。例如,在智能手机领域,Android Linux已经在智能手机开发平台牢牢地占据了一席之地。
Linux相对Windows的优点
-
命令行操作:
Linux兼具图形界面操作(需要使用带有桌面环境的发行版)和完全的命令行操作,可以只用键盘完成一切操作。一旦熟悉命令行操作,用户使用计算机的效率可以得到大幅提高。同时,使用命令行操作对程序员来说能更好地理解计算机的运行原理。 -
安全性:
相对于Windows,Linux更加的安全稳定。虽然不能说Linux一定不会受到病毒侵袭,但Linux比起Windows肯定要安全得多,而且不需要装各种杀毒软件便能正常工作。 -
费用低廉:
Linux 系统上有着大量的可用软件,且绝大多数是免费的,比如声名赫赫的 Apache、Samba、PHP、MySQL 等。从系统到软件,Linux基本都是免费的。而反观Windows却从系统到一些专业软件每一项都需花费上千元。
三、Linux的安装及配置
Windows环境下使用VMware安装Ubuntu
- 下载安装VMware workstation pro(使用密钥激活)
- 下载Ubuntu20.04镜像文件(.iso文件)
- 创建虚拟机
Ubuntu配置及美化
修改软件源并更新系统
- Ubuntu 默认的软件源是境外的,速度上会有些问题,我们可以在「Software & Updates」(软件和更新)中选择国内的镜像(例如阿里云)。
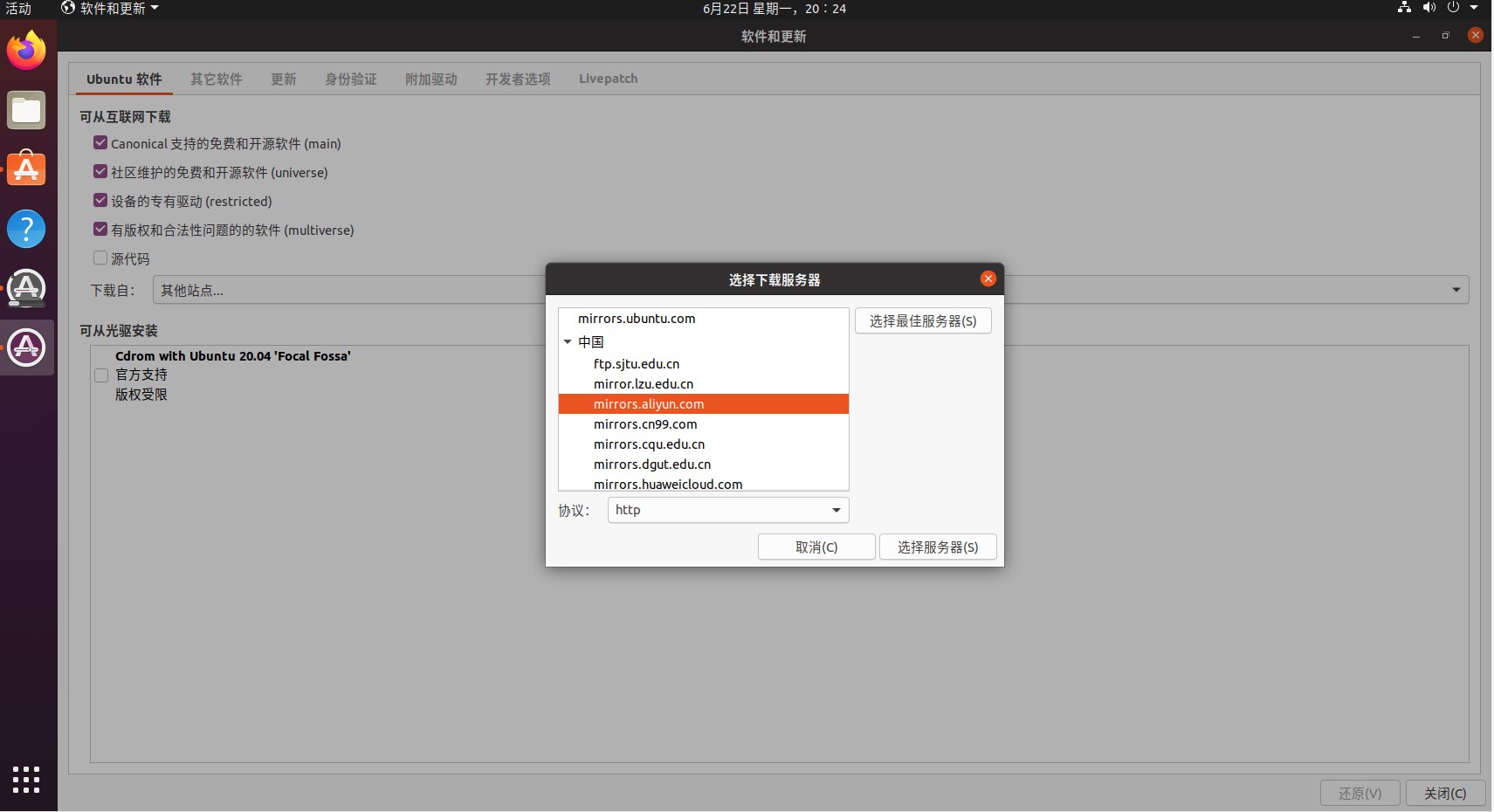
- 修改软件源后需要进行更新
sudo apt update //更新本地包数据库 sudo apt upgrade //更新所有已安装的包 sudo apt autoremove //自动移除不需要的包
桌面美化
安装gnome-tweak-tool及插件
- gnome-tweak-tool可以进行对Gnome shell主题的安装和更改
gnome-shell-extensions 让 gnome 支持插件扩展
chrome-gnome-shell 浏览器扩展支持,可以使用浏览器安装插件
//安装gnome-tweak-tool及安装插件所需工具命令
sudo apt install gnome-tweak-tool
sudo apt install gnome-shell-extensions
sudo apt install chrome-gnome-shell- 进入https://extensions.gnome.org安装插件
插件列表:
dash to dock //自定义dock栏
user themes // 可自由安装主题
hide top bar // 自动隐藏状态栏
下载安装主题及配套图标
- 下载主题(os-catalina-gtk)并解压到/usr/share/themes/(主题网站https://www.gnome-look.org)
- 在tweak中启动主题
- 下载图标并解压到/usr/share/icons(图标网址:https://www.opendesktop.org/s/Gnome/p/1102582/)
- 在tweak中启用图标
- 下载壁纸并使用(壁纸下载地址:https://pixabay.com https://unsplash.com https://wallpapersite.com https://wallpapershome.com)
- 最终效果图:

命令行工具配置及美化
- 安装Terminator
sudo add-apt-repository ppa:gnome-terminator
sudo apt update
sudo apt install terminator可以对Terminnator进行个性化设置(如背景透明,字体颜色等)
- 安装zsh同时将zsh设为默认shell
sudo apt install zsh //安装zsh
sudo chsh -s $(which zsh) //将zsh设为默认shell- 使用oh-my-zsh配置zsh
git clone git://github.com/robbyrussell/oh-my-zsh.git ~/.oh-my-zsh //从GitHub下载oh-my-zsh
cp ~/.oh-my-zsh/templates/zshrc.zsh-template ~/.zshrc //启用oh-my-zsh- 安装zsh插件
- 下载zsh-autosuggestions:命令行命令键入时的历史命令建议插件
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions- 下载zsh-syntaxhighting: 命令行语法高亮插件
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting- 启用插件
vi ~/.zshrc //打开~/.zshrc 文件 plugins=(其他插件名 zsh-autosuggestions zsh-syntax-highlighting) //在plugins这一行加上下载的插件名)
最终效果:
安装一些实用软件
- vim编辑器
sudo apt-get install vim - Git:从GitHub上克隆需要Git
sudo apt install git
四、Linux基本概念及基本操作
1.Linux终端
- 终端的概念:通常我们在使用 Linux 时,并不是直接与系统打交道,而是通过一个叫做 Shell 的中间程序来完成的,在图形界面下为了实现让我们在一个窗口中完成用户输入和显示输出,Linux 系统还提供了一个叫做终端模拟器的程序(Terminal)。 下面是几个比较常见的终端模拟器: gnome-terminal,Konsole,xterm,rxvt,kvt,nxterm 和 eterm 。
- 终端本质上是对应着 Linux 上的 /dev/tty 设备,Linux 的多用户登录就是通过不同的 /dev/tty 设备完成的,Linux 默认提供了 6 个纯命令行界面的 “terminal”(准确的说这里应该是 6 个 virtual consoles)来让用户登录。可以通过使用[Ctrl]+[Alt]+[F1]~[F6]进行切换。
- 示例:
ctrl+alt+F1

ctrl+alt+F2
crtl+alt+F3

crtl+alt+F4

- 示例:
2.shell
- 通常在图形界面中对实际体验带来差异的不是上述的不同发行版的各种终端模拟器,而是这个 Shell(壳)。有壳就有核,这里的核就是指 UNIX/Linux 内核,Shell 是指“提供给使用者使用界面”的软件(命令解析器),类似于 DOS 下的 command(命令行)和后来的 cmd.exe 。普通意义上的 Shell 就是可以接受用户输入命令的程序。它之所以被称作 Shell 是因为它隐藏了操作系统底层的细节。同样的 UNIX/Linux 下的图形用户界面 GNOME 和 KDE,有时也被叫做“虚拟 shell”或“图形 shell”。
- 在 UNIX/Linux 中比较流行的常见的 Shell 有 bash、zsh、ksh、csh 等等(美化中将bash换为了zsh),Ubuntu 终端默认使用的是 bash,默认的桌面环境是 GNOME 或者 Unity(基于 GNOME)。
3.命令行基本操作
- 命令:在 linux 中,最最重要的就是命令,这就包含了 2 个过程,输入和输出。
- 输入:输入当然就是打开终端,然后按键盘输入,然后按回车。
- 输出:输出会返回你想要的结果,比如你要看什么文件,就会返回文件的内容。如果只是执行,执行失败会告诉你哪里错了,如果执行成功那么会没有输出。
- 常用命令行快捷键
| 按键 | 作用 |
|---|---|
| ↑ | 显示历史命令 |
| Tab | 补全命令,目录,命令参数 |
| CTRL+c | 终止当前程序 |
| CTRL+d | 终止当前程序/键盘输入结束/退出终端 |
| CTRL+s | 暂停当前程序,暂停后按任意键恢复运行 |
| CTRL+z | 将当前程序放到后台运行,恢复到前台命令为fg |
| CTRL+a | 将光标移至输入的行头 |
| CTRL+e | 将光标移至输入的行尾 |
| CTRL+k | 删除从光标所在位置到行末的输入 |
| ALT+Backspace | 删除输入中的一个单词(以空格为区分) |
- man命令(获取用户手册)
- 在 Linux 环境中,如果你遇到困难,可以使用man命令,它是Manual pages的缩写。Manual pages 是 UNIX 或类 UNIX 操作系统中在线软件文档的一种普遍的形式, 内容包括计算机程序(包括库和系统调用)、正式的标准和惯例,甚至是抽象的概念。用户可以通过执行man命令调用手册页。
- man命令基本使用方法:
man command_name
4.通配符
- 通配符概念:
- 通配符是一种特殊语句,主要有星号(*)和问号(?),用来对字符串进行模糊匹配(比如文件名、参数名)。
- 当查找文件夹时,可以使用它来代替一个或多个真正字符;当不知道真正字符或者懒得输入完整名字时,常常使用通配符代替一个或多个真正字符。
- 终端里面输入的通配符是由 Shell 处理的,不是由所涉及的命令语句处理的,它只会出现在命令的“参数值”里(它不能出现在命令名称里, 命令不记得,那就用Tab补全)。当 Shell 在“参数值”中遇到了通配符时,Shell 会将其当作路径或文件名在磁盘上搜寻可能的匹配:若符合要求的匹配存在,则进行代换(路径扩展);否则就将该通配符作为一个普通字符传递给“命令”,然后再由命令进行处理。总之,通配符实际上就是一种 Shell 实现的路径扩展功能。在通配符被处理后, Shell 会先完成该命令的重组,然后继续处理重组后的命令,直至执行该命令。
- 例如通配符
*:匹配零或多个字符

五、Linux用户及用户组管理
- Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
- 用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
- 每个用户账号都拥有一个唯一的用户名和各自的口令(password)。
- 用户在登录时键入正确的用户名和口令后,就能够进入系统和自己的主目录。
1.查看用户
who命令查看用户:who命令的常用参数:
| 参数 | 作用 |
|---|---|
| -a | 打印全部信息 |
| -d | 打印死掉的进程 |
| -m | 显示当前伪终端用户的用户名 |
| -q | 打印当前登录的用户数和用户名 |
| -u | 打印当前登录用户的登录信息 |
| -r | 打印运行等级 |
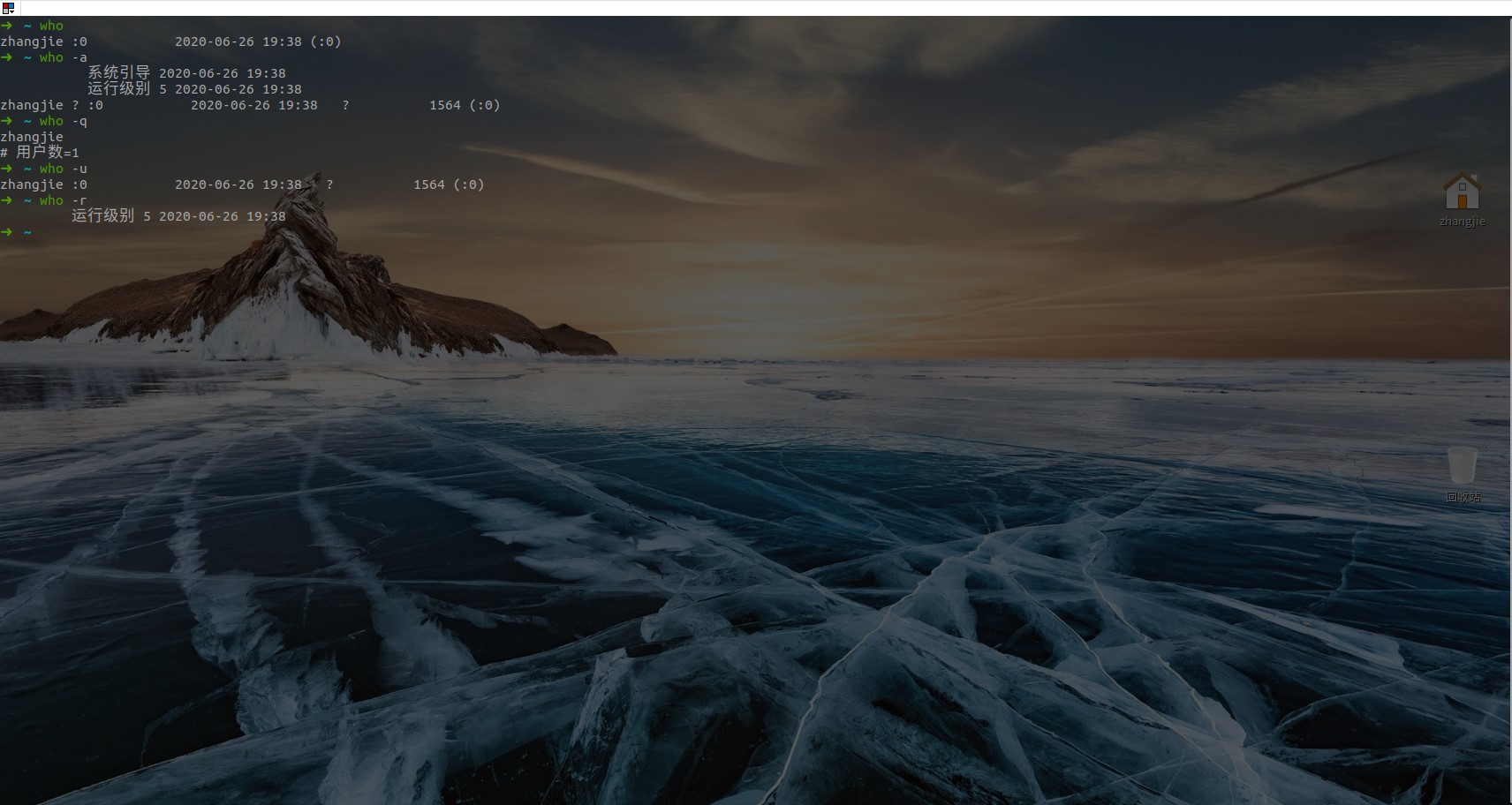
注:whoami命令可查看当前登录用户的用户名
2.创建用户
- root账户:在 Linux 系统里, root 账户拥有整个系统至高无上的权限,比如新建和添加用户。
sudo命令:一般我们登录系统时都是以普通账户的身份登录的,要创建用户需要 root 权限,这里就要用到 sudo 这个命令了。sudo <cmd>可以以特权级别运行 cmd 命令,需要当前用户属于 sudo 组,且需要输入当前用户的密码(注:Linux环境输入密码不会有显示)su命令:su <user>可以切换到用户 user,执行时需要输入目标用户的密码;su - <user>命令也是切换用户,但是同时用户的环境变量和工作目录也会跟着改变成目标用户所对应的。- 创建用户:
sudo adduser uername - 切换用户:
su username

3.用户组
- 用户组简介:在 Linux 里面每个用户都有一个归属(用户组),用户组简单地理解就是一组用户的集合,它们共享一些资源和权限,同时拥有私有资源。
- 查看用户组:
- 法一:
groups + username
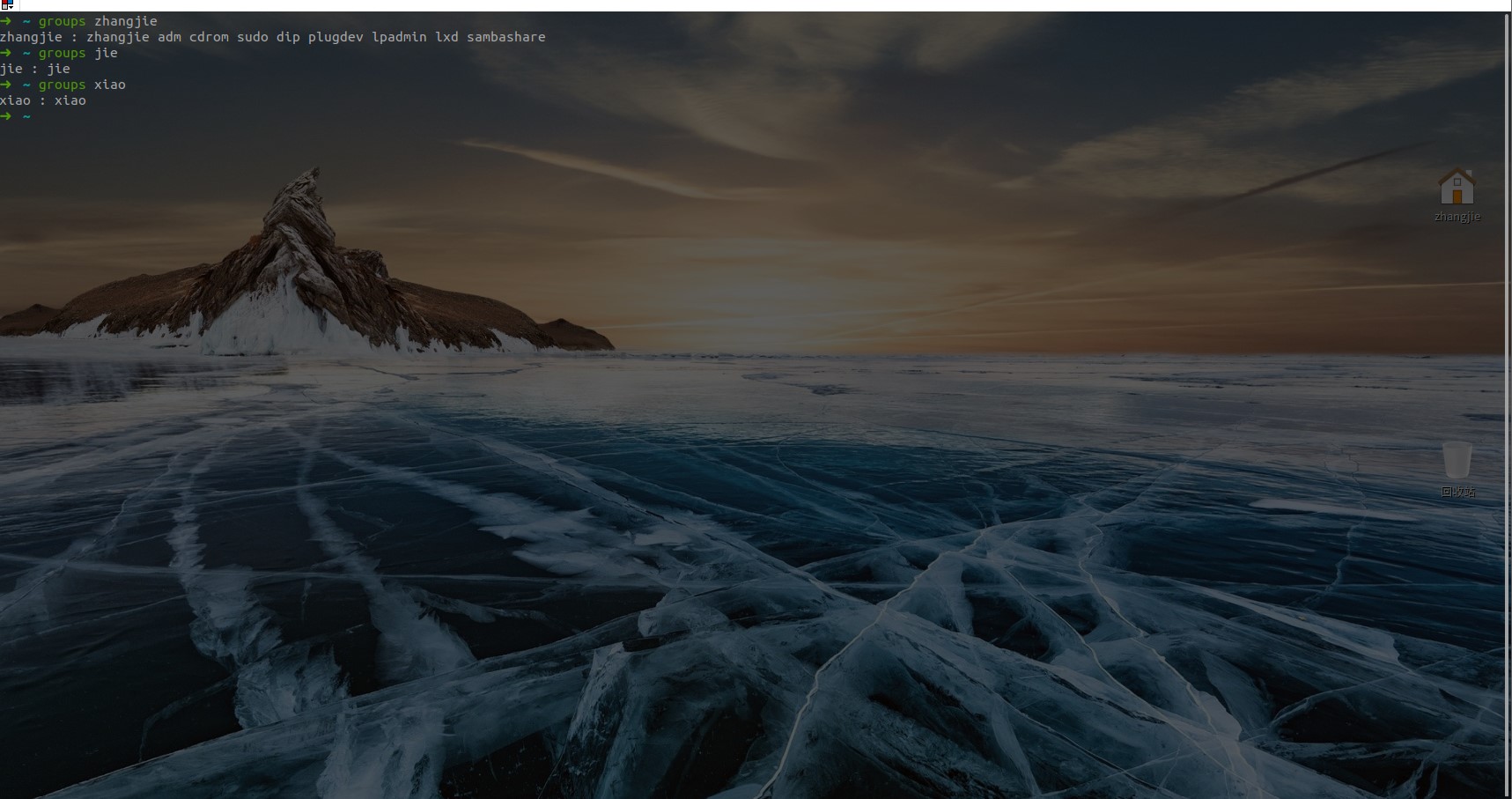
其中冒号之前表示用户,后面表示该用户所属的用户组。每次新建用户如果不指定用户组的话,默认会自动创建一个与用户名相同的用户组(差不多就相当于家长的意思)。 - 法二:
cat /etc/group(查看/etc/group目录)- /etc/group 的内容包括用户组(Group)、用户组口令、GID(组 ID) 及该用户组所包含的用户(User),每个用户组一条记录。格式如下:
group_name:password:GID:user_list
- 示例:

你看到上面的 password 字段为一个 x,并不是说密码就是它,只是表示密码不可见而已。这里需要注意,如果用户的 GID 等于用户组的 GID,那么最后一个字段 user_list 就是空的
- /etc/group 的内容包括用户组(Group)、用户组口令、GID(组 ID) 及该用户组所包含的用户(User),每个用户组一条记录。格式如下:
- 法一:
删除用户和用户组
- 删除用户:
sudo deluser username --remove-home - 删除用户组:
sudo groupdel username --remove-home
六、Linux文件类型及权限
文件类型
- 普通文件(regular file):一般存取的文件。大致可分为
- 纯文本文件(ASCII):这是Unix系统中最多的一种文件类型,之所以称为纯文本文件,是因为内容可以直接读到的数据,例如数字、字母等等。设 置文件几乎都属于这种文件类型。
- 二进制文件(binary):系统其实仅认识且可以执行二进制文件(binary file)。Linux中的可执行文件(脚本,文本方式的批处理文件不算)就是这种格式的。举例来说,命令cat就是一个二进制文件。
- 数据格式的文件(data):有些程序在运行过程中,会读取某些特定格式的文件,那些特定格式的文件可以称为数据文件(data file)。
- 目录文件(directory):就是目录。
- 软链接文件(link):类似Windows下面的快捷方式。
- 设备与设备文件(device):与系统外设及存储等相关的一些文件,通常都集中在 /dev目录。通常又分为两种:
- 块设备文件:就是存储数据以供系统存取的接口设备,简单而言就是硬盘。
- 字符设备文件:即串行端口的接口设备,例如键盘、鼠标等等。
- 套接字(sockets):这类文件通常用在网络数据连接。可以启动一个程序来监听客户端的要求,客户端就可以通过套接字来进行数据通信。
- 管道(FIFO,pipe):FIFO是first-in-first-out(先进先出)的缩写。管道分为匿名管道和命名管道。管道都是一端写入、另一端读取,它们是单方向数据传输的,它们的数据都是直接在内存中传输的,管道是进程间通信的一种方式,例如父进程写,子进程读。
文件权限
- 文件权限就是文件的访问控制权限,即哪些用户和组群可以访问文件以及可以执行什么样的操作。
- Unix/Linux 系统是一个典型的多用户系统,不同的用户处于不同的地位,对文件和目录有不同的访问权限。为了保护系统的安全性,Unix/Linux 系统除了对用户权限作了严格的界定外,还在用户身份认证、访问控制、传输安全、文件读写权限等方面作了周密的控制。
- 在 Unix/Linux 中的每一个文件或目录都包含有访问权限,这些访问权限决定了谁能访问和如何访问这些文件和目录。
查看文件管理权限
- 使用
ls命令(ls相当于list的缩写)ls -l使用较长格式列出文件

- 参数含义:

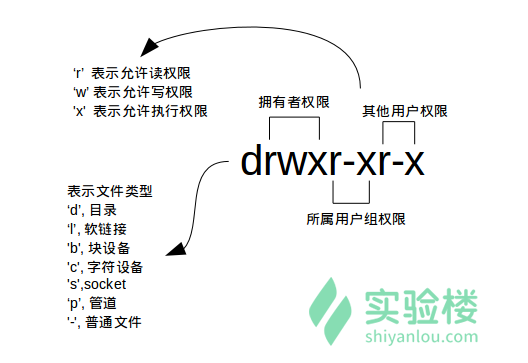
- 文件权限:
- 读权限,表示你可以使用
cat <file name>之类的命令来读取某个文件的内容; - 写权限,表示你可以编辑和修改某个文件的内容;
- 执行权限,通常指可以运行的二进制程序文件或者脚本文件,如同 Windows 上的 exe 后缀的文件,不过 Linux 上不是通过文件后缀名来区分文件的类型。
- 注意:一个目录同时具有读权限和执行权限才可以打开并查看内部文件,而一个目录要有写权限才允许在其中创建其它文件,这是因为目录文件实际保存着该目录里面的文件的列表等信息。
- 读权限,表示你可以使用
ls命令参数:ls -l:使用较长格式列出文件ls -a:显示除了 .(当前目录)和 …(上一级目录)之外的所有文件,包括隐藏文件(Linux 下以 . 开头的文件为隐藏文件)(-a 相当于all)

ls -al:同时使用-a和-l参数:

ls dl <目录名>:查看某一个目录的完整属性,而不是显示目录里面的文件属性

ls -asSh:显示所有文件大小,并以普通人类能看懂的方式呈现。其中小 s 为显示文件大小,大 S 为按文件大小排序,若需要知道如何按其它方式排序,可以使用 man ls 命令查询。

变更文件所有者
- 变更文件所有者
chown <username> <filename>:其中 chown 是change owner 的缩写 - 变更文件所属群组
chgrp <usergroupname> <filename>:其中 chgrp 是change group的缩写
修改文件权限
- 加减修改法:
- 示例:
chmod g-w zhangjie.txt
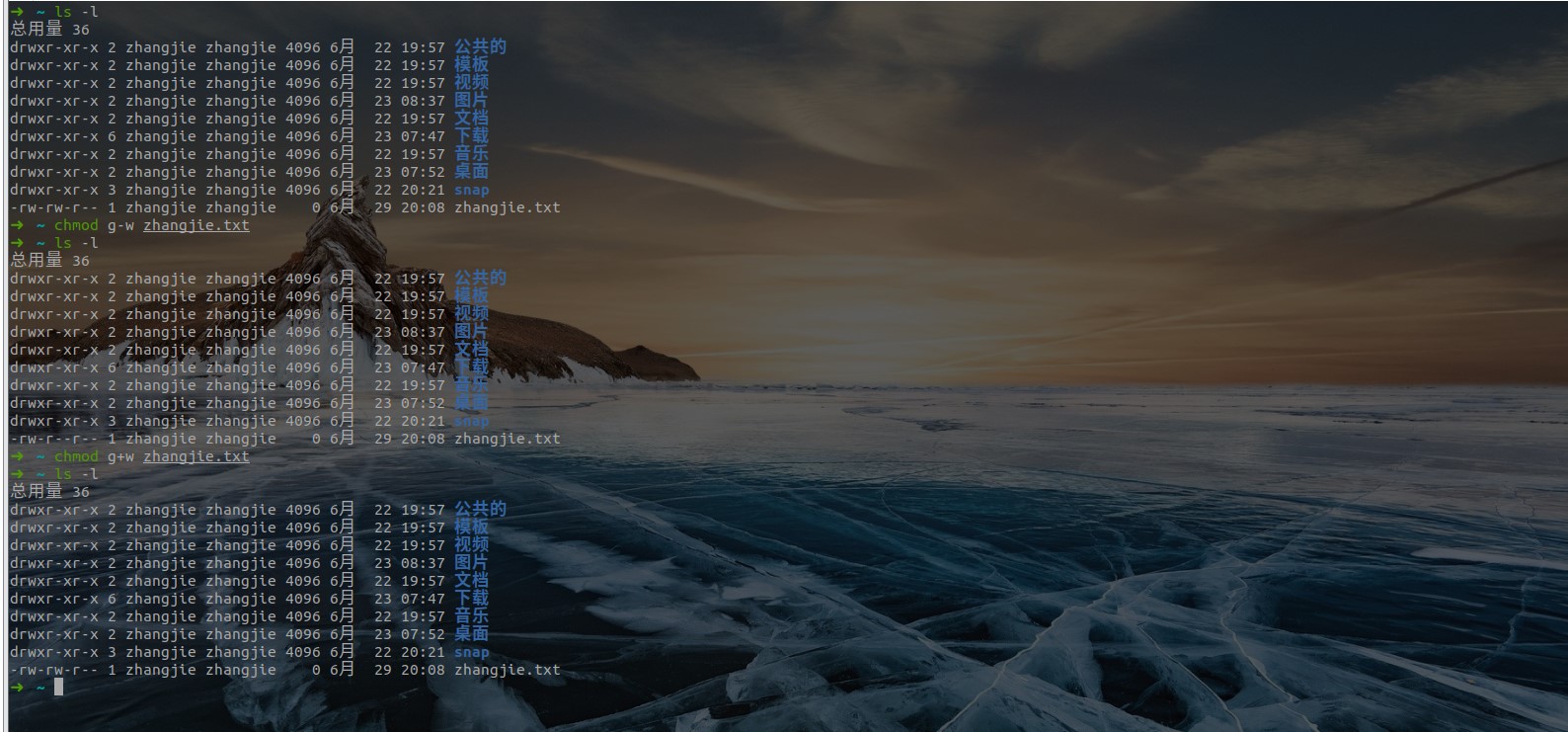
g、o 还有 u 分别表示 group(用户组)、others(其他用户) 和 user(用户),+ 和 - 分别表示增加和去掉相应的权限。
- 示例:
七、Linux目录结构及文件基本操作
Linux目录结构与Windows区别
- Linux 的目录与 Windows 的目录的区别:或许对于一般操作上的感受来说没有多大不同,但从它们的实现机制来说是完全不同的。
- 一种不同是体现在目录与存储介质(磁盘,内存,DVD 等)的关系上,以往的 Windows 一直是以存储介质为主的,主要以盘符(C 盘,D 盘…)及分区来实现文件管理,然后之下才是目录,目录就显得不是那么重要,除系统文件之外的用户文件放在任何地方任何目录也是没有多大关系。所以通常 Windows 在使用一段时间后,磁盘上面的文件目录会显得杂乱无章。
- 然而 UNIX/Linux 恰好相反,UNIX 是以目录为主的,Linux 也继承了这一优良特性。 Linux 是以树形目录结构的形式来构建整个系统的,可以理解为树形目录是一个用户可操作系统的骨架。虽然本质上无论是目录结构还是操作系统内核都是存储在磁盘上的,但从逻辑上来说 Linux 的磁盘是“挂在”(挂载在)目录上的,每一个目录不仅能使用本地磁盘分区的文件系统,也可以使用网络上的文件系统。举例来说,可以利用网络文件系统(Network File System,NFS)服务器载入某特定目录等。
- Linux中每一个文件在此目录树中的文件名(包含完整路径)都是独一无二的。
Linux的目录结构-FHS标准
FHS简介
- FHS(英文:Filesystem Hierarchy Standard 中文:文件系统层次结构标准),多数 Linux 版本采用这种文件组织形式,FHS 定义了系统中每个区域的用途、所需要的最小构成的文件和目录同时还给出了例外处理与矛盾处理。
- FHS 定义了两层规范,第一层是, /(根目录) 下面的各个目录应该要放什么文件数据,例如 /etc 应该放置设置文件,/bin 与 /sbin 则应该放置可执行文件等等。
第二层则是针对 /usr 及 /var 这两个目录的子目录来定义。例如 /var/log 放置系统日志文件,/usr/share 放置共享数据等等。 - FHS 是根据以往无数 Linux 用户和开发者的经验总结出来的,并且会维持更新,FHS 依据文件系统使用的频繁与否以及是否允许用户随意改动(注意,不是不能,学习过程中,不要怕这些),将目录定义为四种交互作用的形态,如下表所示:
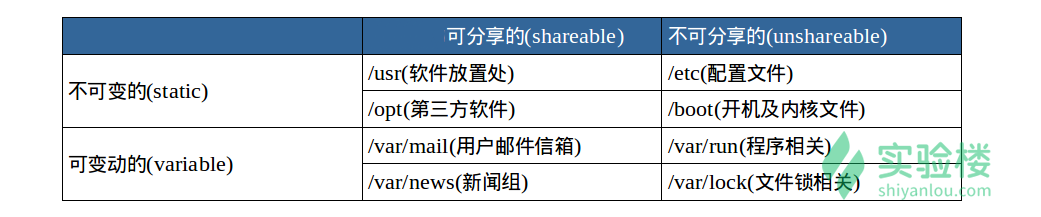
- 可分享的:可以分享给其他系统挂载使用的目录,所以包括执行文件与用户的邮件等数据, 是能够分享给网络上其他主机挂载用的目录;
- 不可分享的:自己机器上面运作的装置文件或者是与程序有关的socket文件等, 由于仅与自身机器有关,所以当然就不适合分享给其他主机了。
- 不变的:有些数据是不会经常变动的,跟随着distribution而不变动。 例如函式库、文件说明文件、系统管理员所管理的主机服务配置文件等等;
- 可变动的:经常改变的数据,例如登录文件、一般用户可自行收受的新闻组等。
FHS标准下目录结构
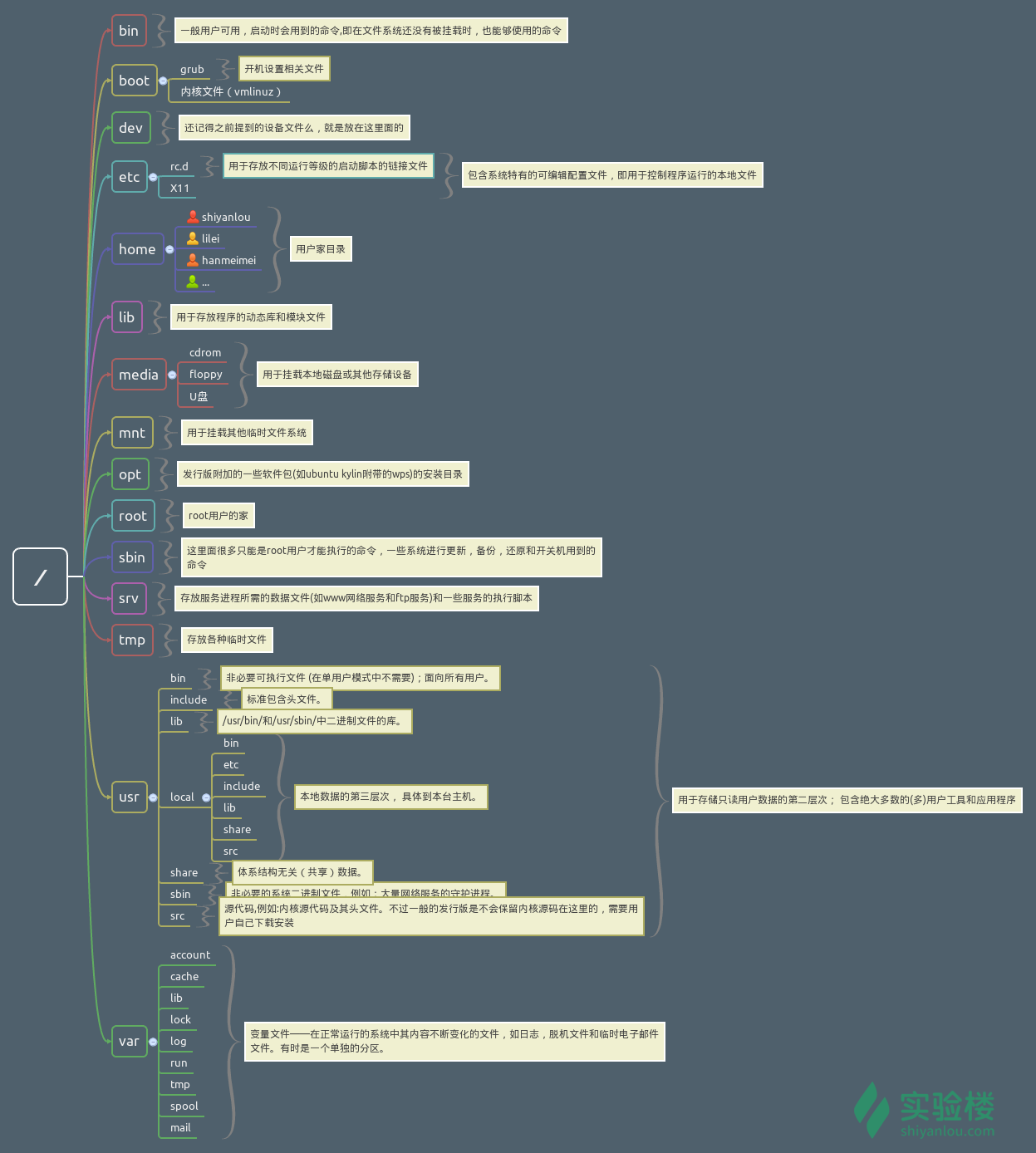
- 用户安装的软件一般安装到
/usr/local目录下,其中bin目录放可执行文件,src放源代码文件等。
真机演示:
利用tree命令可查看目录树:

Linux的目录路径
路径定义及分类
- 路径定义:顾名思义,路径就是你要去哪儿的路线。如果你想进入某个具体的目录或者想获得某个目录的文件(目录本身也是文件)那就得用路径来找到。
- 路径类型:
- 绝对路径:以根" / "目录为起点的完整路径,以你所要到的目录为终点,表现形式如: /usr/local/bin,表示根目录下的 usr 目录中的 local 目录中的 bin 目录。
- 相对路径:相对路径,也就是相对于你当前的目录的路径,相对路径是以当前目录" . “为起点,以你所要到的目录为终点,表现形式如: usr/local/bin (这里假设你当前目录为根目录)。(注意:我们表示相对路径实际并没有加上表示当前目录的那个” ." ,而是直接以目录名开头,因为这个 usr 目录为 / 目录下的子目录,是可以省略这个 . 的;如果是当前目录的上一级目录,则需要使用" …" ,比如你当前目录为 /home/zhangjie 目录下,根目录就应该表示为 …/…/ ,表示上一级目录( home 目录)的上一级目录( / 目录)。)
与路径相关命令
cd(change directory/改变目录)命令:(注:cd 命令与后面参数间都有一个空格)- 进入上一级目录:
cd .. - 进入子目录:
cd <目录名> - 进入具体目录:
cd <绝对路径>或cd <相对路径> - 返回home目录:
cd或cd /home/<username>或cd ~ - 返回进入此目录之前所在目录:
cd - - 进入当前用户的家目录下:
cd ~. - 把上个cd命令的参数作为cd参数使用:
cd !$
- 进入上一级目录:
- pwd(print working directory/显示当前工作目录)命令:(注:显示的是绝对路径)
示例:
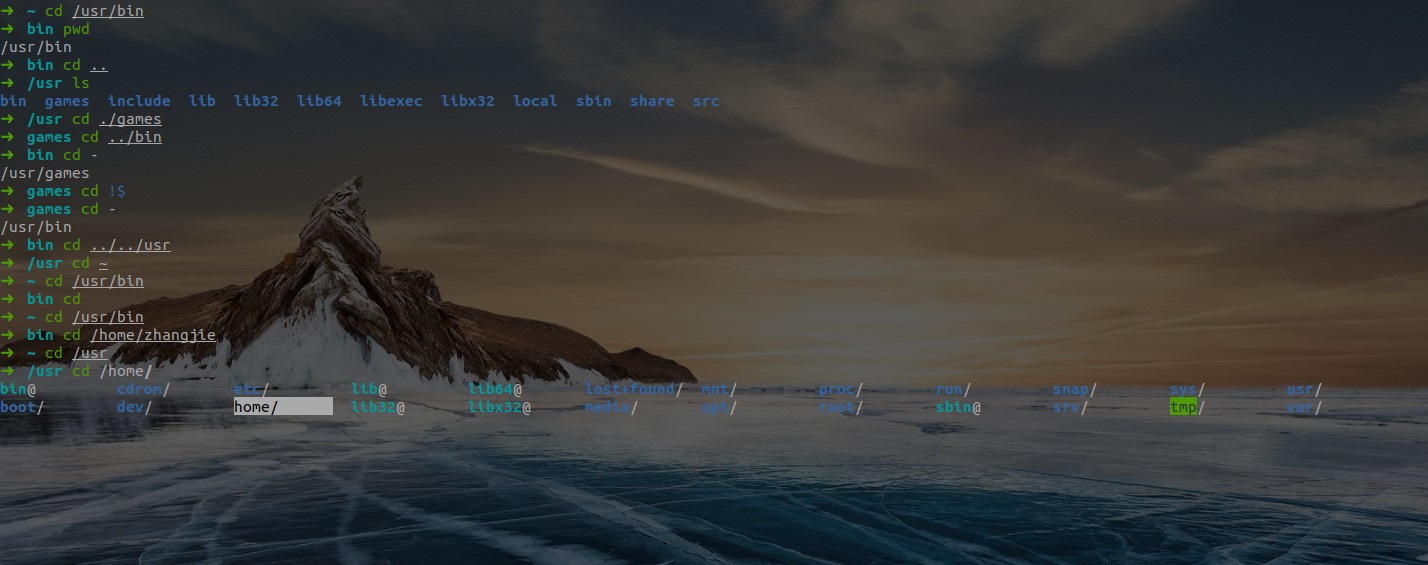
cd /usr/bin:以绝对路径进入cd ./games:以相对路径进入(在当前目录下,进入games目录)cd ../../usr:以相对路径进入(在当前目录的上两级目录下,进入usr目录)- 技巧:输入cd后按Tab可显示当前目录下所有子目录,继续按Tab可顺序选择,按Shift+Tab可逆向选择
Linux的文件基本操作
新建
-
新建空白文件
touch <filename>:使用 touch 命令创建空白文件,在不加任何参数的情况下,只指定一个文件名,则可以创建一个指定文件名的空白文件(不会覆盖已有同名文件,也可以同时创建多个文件)。
-
新建目录
mkdir <directoryname>:使用 mkdir(make directories)命令可以创建一个空目录。mkdir 相对路径/绝对路径:使用 -p 参数,同时创建父目录(如果不存在该父目录)。
-
示例:
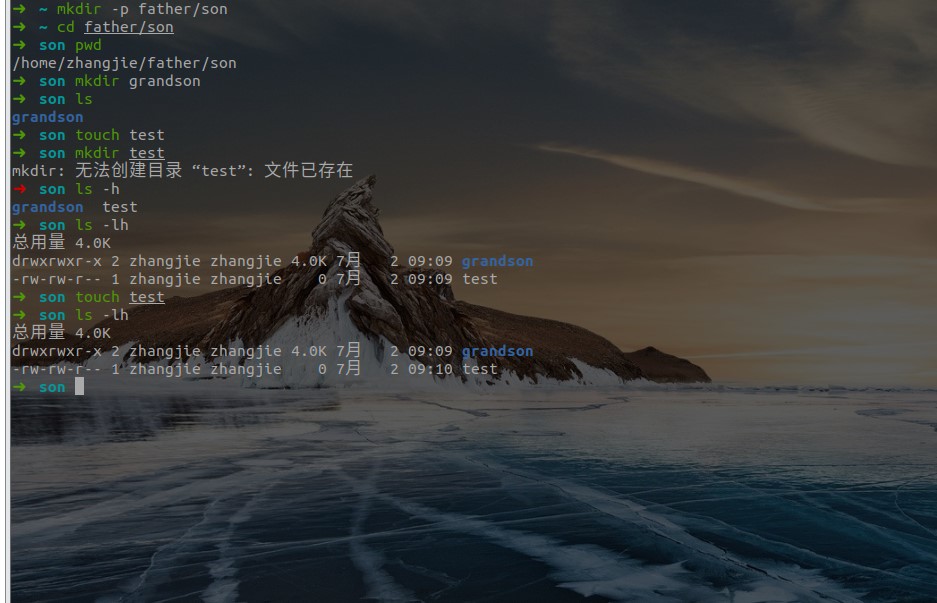
-
注:
- 若当前目录已经创建了一个 test 文件,再使用 mkdir test 新建同名的文件夹,系统会报错文件已存在。这符合 Linux 一切皆文件的理念。
- 若当前目录存在一个 test 文件夹,则 touch 命令,则会更改该文件夹的时间戳而不是新建文件(touch命令本来的主要用途就是更改时间戳的)。
复制
-
复制文件
cp <文件名> <目录名>:使用 cp 命令(copy)复制一个文件到指定目录.- 示例:

cp <文件名> <目录名+要改的文件名>:改名复制,如果复制的目标位置已经存在同名的文件,则会提示是否覆盖。
-
复制目录:
cp -r <待复制目录路径(相对与绝对均可)> <要复制到的目录名>:要成功复制目录需要加上 -r 或者 -R 参数,表示递归复制。- 示例:

删除
-
删除文件
rm <文件名>:使用 rm(remove files or directories)命令删除文件(可同时删除多个文件)- 示例:

rm -f <文件名>:有时候会遇到想要删除一些为只读权限的文件,若想强制删除文件,可以使用 -f 参数强制删除:
-
删除目录
rm -r <目录名>:要删除一个目录,需要加上 -r 或 -R 参数。rm -rf <目录名>:强制删除。rm -rf /*命令,执行后效果如下

rm是删除命令,-r选项是删除目录,-f选项是强制删除,/*中/是用户的根目录,而*是通配符,代表根目录下的全部文件。所以这个命令是删除用户根目录下的全部文件。- 但是因为这个用户不是root用户,所以不具有删除根目录下所有文件的权限,所以会出现大量无法删除。
- 示例:

打开可执行文件
- 在终端输入可执行的文件的全路径(绝对或相对均可)就可运行相应可执行文件
- 示例:在当前目录下运行a.out文件的命令:
./a.out
移动文件与文件重命名
-
移动文件(类似Windows的剪切粘贴)
mv <待移动的文件名> <目的目录名>:使用 mv(move or rename files)命令移动文件.
-
重命名文件
mv <原文件名> <新命名的文件名>:mv 命令除了能移动文件外,还能给文件重命名。
-
示例:

查看文件内容
-
cat命令查看cat <filename>: 打印文件内容到终端(正序显示)。cat -n <filename>: 加上 -n 参数显示行号。- 示例
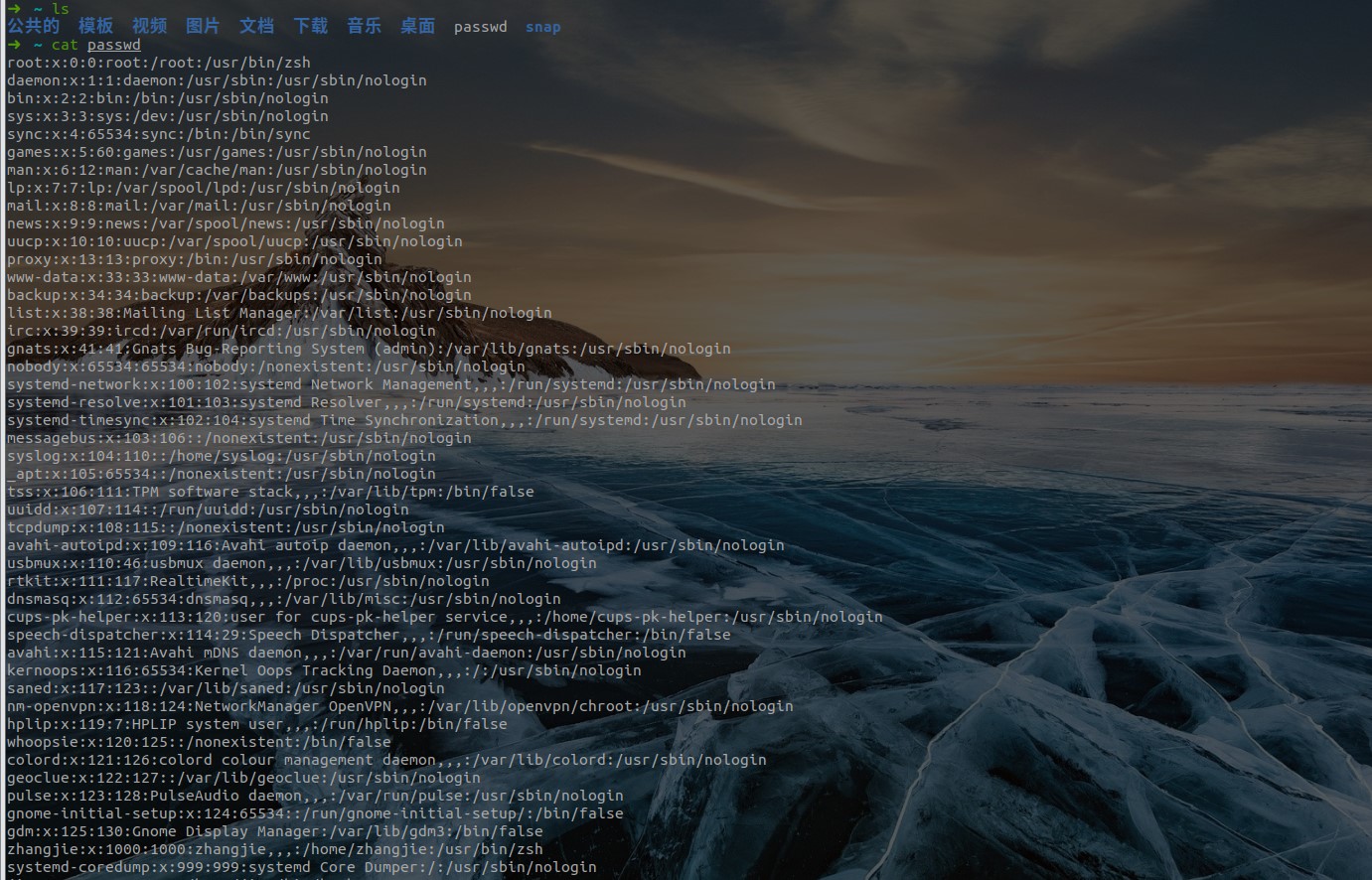

-
tac命令查看tac <filename>:打印文件内容到终端(逆序显示)。
-
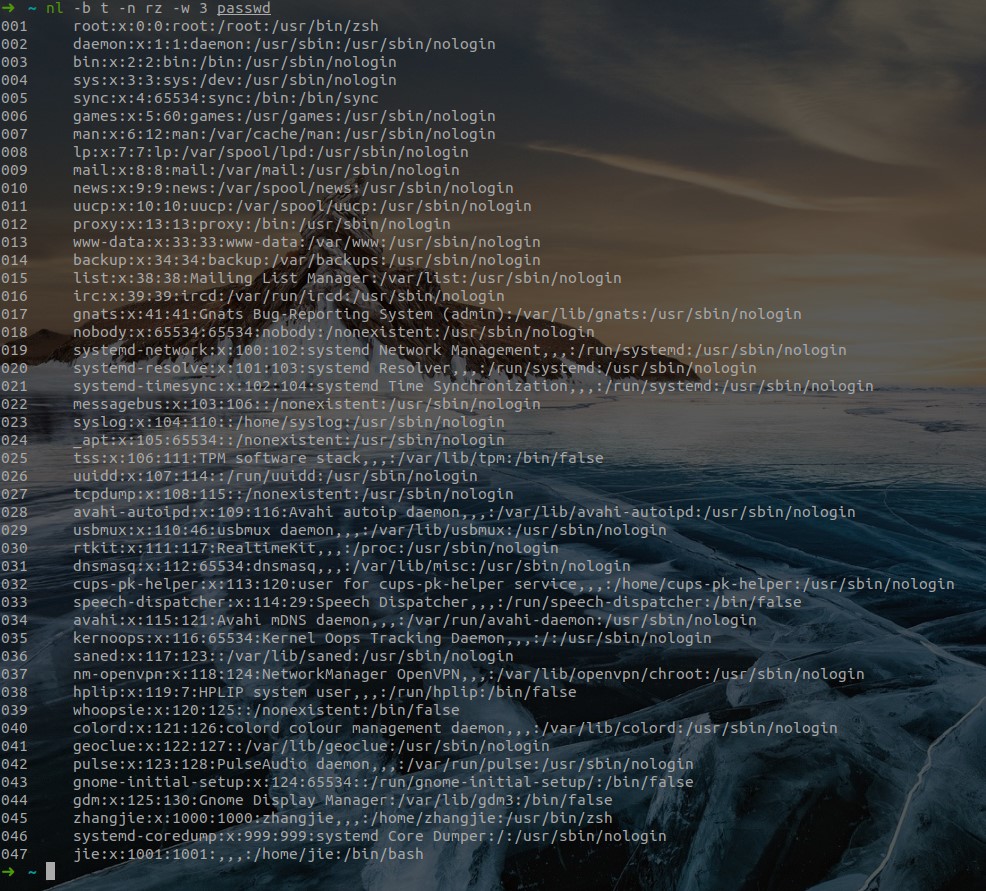
nl命令查看- 主要参数:
- -b : 指定添加行号的方式,主要有两种:
- -b a:表示无论是否为空行,同样列出行号("cat -n"就是这种方式)
- -b t:只列出非空行的编号并列出(默认为这种方式)
- -n : 设置行号的样式,主要有三种:
- -n ln:在行号字段最左端显示
- -n rn:在行号字段最右边显示,且不加 0
- -n rz:在行号字段最右边显示,且加 0
- -w : 行号字段占用的位数(默认为 6 位)
- -b : 指定添加行号的方式,主要有两种:
nl 参数 <文件名>:添加行号并打印,这是个比 cat -n 更专业的行号打印命令。- 示例:
- 主要参数:
-
使用
more和less命令分页查看文件- more功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上。 more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示;按 b 键就会往回(back)一页显示;按Enter 向下n行,需要定义,默认为1行;按下 h 显示帮助,q 退出。
- less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大。less 的用法比起 more 更加的有弹性。 在 more 的时候,我们并没有办法向前面翻, 只能往后面看,但若使用了 less 时,就可以使用 [pageup] [pagedown] 等按 键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!
- 示例:

-
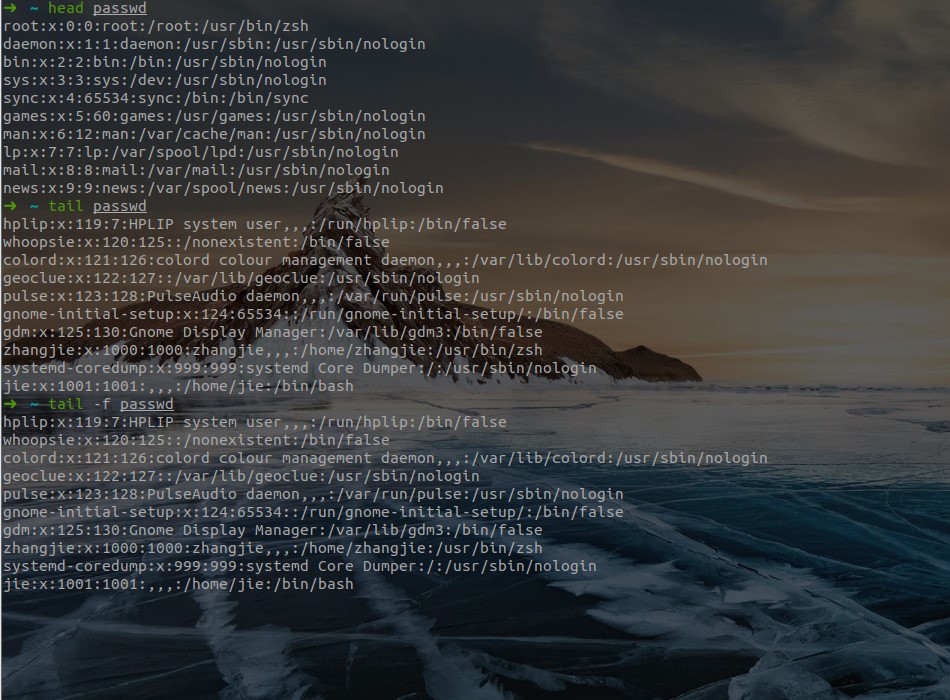
使用
head和tail命令查看文件:head命令可以将一段文本的开头一部分输出到标准输出。tail将一段文本的结尾一部分输出到标准输出,也就是从某个节点位置开始输出。tail命令,不得不提的还有它一个很牛的参数 -f,这个参数可以实现不停地读取某个文件的内容并显示。这可以让我们动态查看日志,达到实时监视的目的。- 示例:
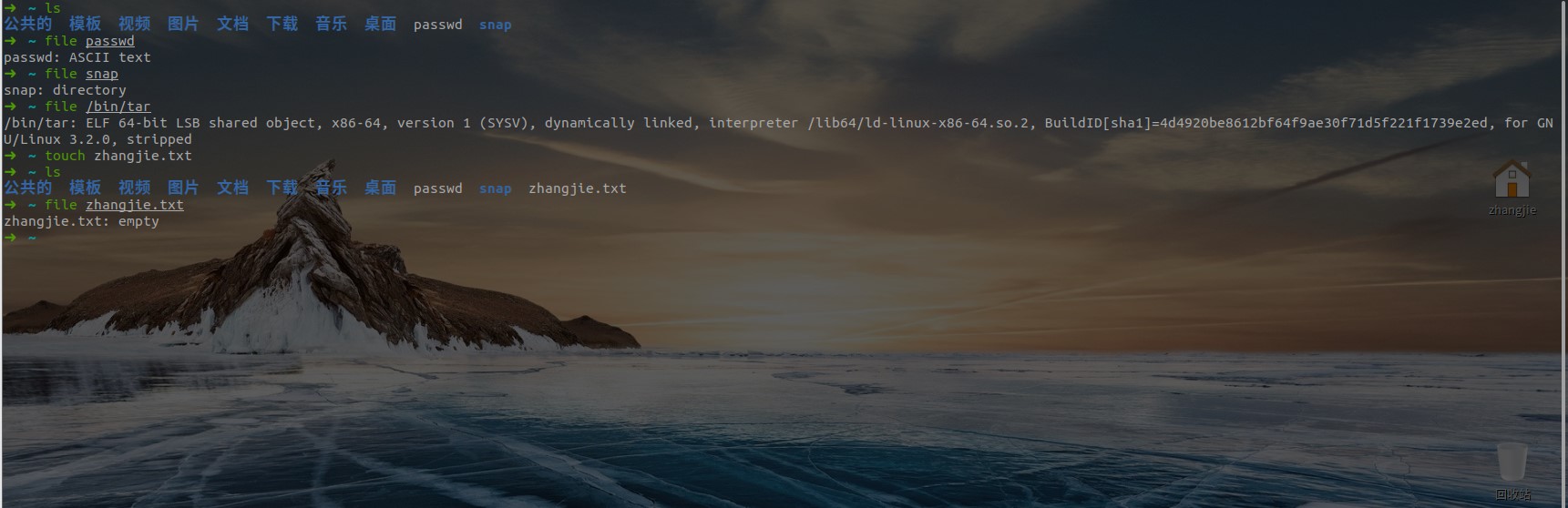
查看文件类型
file <filename>:使用 file 命令查看文件的类型。- 与 Windows 不同的是,如果你新建了一个 zhangjie.txt 文件,Windows 会自动把它识别为文本文件,而 file 命令会识别为一个空文件。在 Linux 中文件的类型不是根据文件后缀来判断的。当你在文件里输入内容后才会显示文件类型。
- 示例:
编辑文件
- 在 Linux 下面编辑文件通常我们会直接使用专门的命令行编辑器比如(emacs,vim,nano)。
- 例如vim编辑器,它的使用方法可以使用
vimtutor命令在Linux终端中直接查看。 - 示例:
文件查找
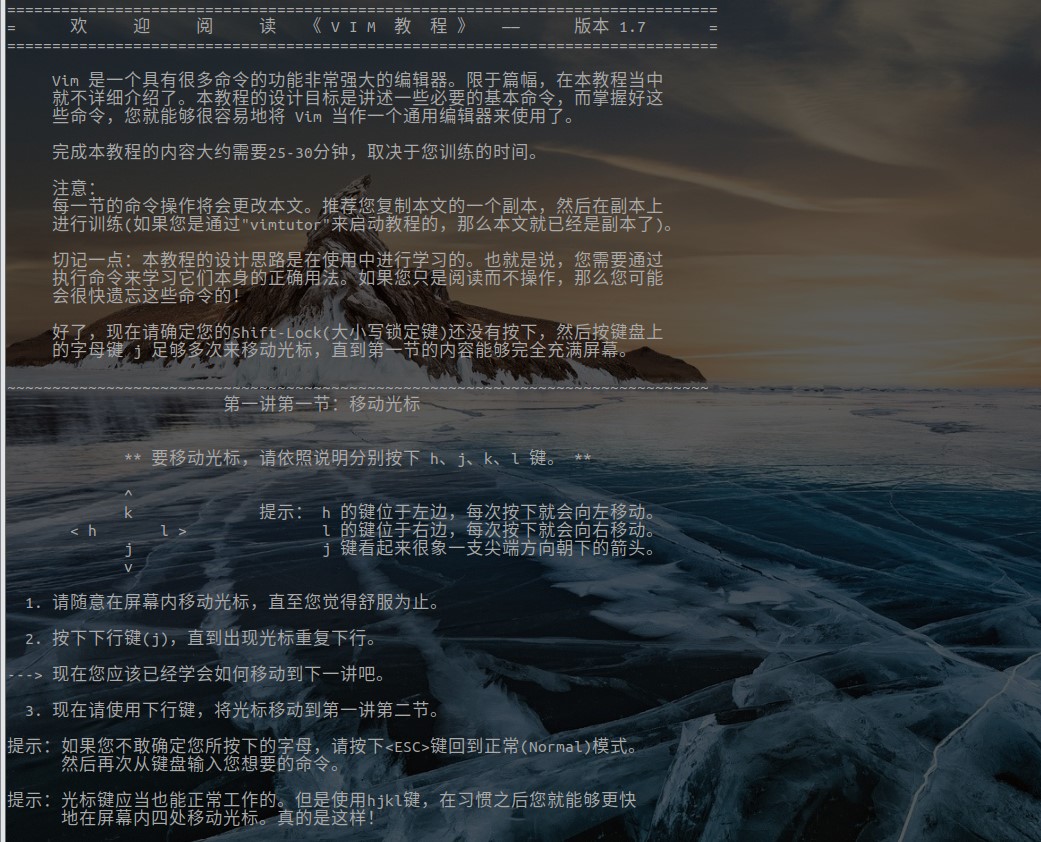
whereis:whereis 只能搜索二进制文件(-b),man 帮助文件(-m)和源代码文件(-s)。这个搜索很快,因为它并没有从硬盘中依次查找,而是直接从数据库中查询。
locate:- 使用 locate 命令查找文件也不会遍历硬盘,它通过查询 /var/lib/mlocate/mlocate.db 数据库来检索信息。不过这个数据库也不是实时更新的,系统会使用定时任务每天自动执行 updatedb 命令来更新数据库。所以有时候你刚添加的文件,它可能会找不到,需要手动执行一次 updatedb 命令。注意这个命令不是内置的命令,需要手动安装
sudo apt-get install locate,然后执行更新。 - 如果想只统计数目可以加上 -c 参数,-i 参数可以忽略大小写进行查找,whereis 的 -b、-m、-s 同样可以使用。
- 它可以用来查找指定目录下的不同文件类型。

- 使用 locate 命令查找文件也不会遍历硬盘,它通过查询 /var/lib/mlocate/mlocate.db 数据库来检索信息。不过这个数据库也不是实时更新的,系统会使用定时任务每天自动执行 updatedb 命令来更新数据库。所以有时候你刚添加的文件,它可能会找不到,需要手动执行一次 updatedb 命令。注意这个命令不是内置的命令,需要手动安装
which:which 本身是 Shell 内建的一个命令,我们通常使用 which 来确定是否安装了某个指定的程序。使用which我们可以看到某个系统命令是否存在以及执行的到底是哪一个地方的命令。

find:- find 应该是这几个命令中最强大的了,它不但可以通过文件类型、文件名进行查找而且可以根据文件的属性(如文件的时间戳,文件的权限等)进行搜索。
- 注意 find 命令的路径是作为第一个参数的, 基本命令格式为 find [path][option] [action] 。
find命令参数:
-name filename #查找名为filename的文件
-perm #按执行权限来查找
-user username #按文件属主来查找
-group groupname #按组来查找
-mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前
-atime -n +n #按文件访问时间来查找文件,-n指n天以内,+n指n天以前
-ctime -n +n #按文件创建时间来查找文件,-n指n天以内,+n指n天以前
-nogroup #查无有效属组的文件,即文件的属组在/etc/groups中不存在
-nouser #查无有效属主的文件,即文件的属主在/etc/passwd中不存
-type b/d/c/p/l/f #查是块设备、目录、字符设备、管道、符号链接、普通文件
-size n[c] #查长度为n块[或n字节]的文件
-mount #查文件时不跨越文件系统mount点
-follow #如果遇到符号链接文件,就跟踪链接所指的文件
-prune #忽略某个目录- 示例:

文件内容查找
grep命令:Linux grep 命令用于查找文件里符合条件的字符串。- grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为
-,则grep 指令会从标准输入设备读取数据。 - 语法:
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...] - 参数:
-a 或 --text : 不要忽略二进制的数据。
-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 --count : 计算符合样式的列数。
-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F 或 --fixed-regexp : 将样式视为固定字符串的列表。
-G 或 --basic-regexp : 将样式视为普通的表示法来使用。
-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-i 或 --ignore-case : 忽略字符大小写的差别。
-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 --only-matching : 只显示匹配PATTERN 部分。
-q 或 --quiet或–silent : 不显示任何信息。
-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
-s 或 --no-messages : 不显示错误信息。
-v 或 --invert-match : 显示不包含匹配文本的所有行。
-V 或 --version : 显示版本信息。
-w 或 --word-regexp : 只显示全字符合的列。
-x --line-regexp : 只显示全列符合的列。
-y : 此参数的效果和指定"-i"参数相同。
文件打包与解压缩
- 压缩包文件格式
| 文件后缀名 | 说明 |
|---|---|
| *.zip | zip 程序打包压缩的文件 |
| *.rar | rar 程序压缩的文件 |
| *.7z | 7zip 程序压缩的文件 |
| *.tar | tar 程序打包,未压缩的文件 |
| *.gz | gzip 程序(GNU zip)压缩的文件 |
| *.xz | xz 程序压缩的文件 |
| *.bz2 | bzip2 程序压缩的文件 |
| *.tar.gz | tar 打包,gzip 程序压缩的文件 |
| *.tar.xz | tar 打包,xz 程序压缩的文件 |
| *tar.bz2 | tar 打包,bzip2 程序压缩的文件 |
| *.tar.7z | tar 打包,7z 程序压缩的文件 |
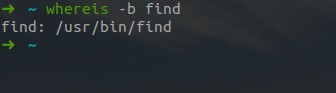
- zip压缩打包程序
zip命令使用基本格式:zip [选项] 压缩包名 源文件或源目录列表- 常用参数:
| 选项 | 含义 |
|---|---|
| -r | 递归压缩目录,即将制定目录下的所有文件以及子目录全部压缩。 |
| -m | 将文件压缩之后,删除原始文件,相当于把文件移到压缩文件中。 |
| -v | 显示详细的压缩过程信息。 |
| -q | 在压缩的时候不显示命令的执行过程。 |
| -压缩级别 | 压缩级别是从 1~9 的数字,-1 代表压缩速度更快,-9 代表压缩效果更好。 |
| -u | 更新压缩文件,即往压缩文件中添加新文件。 |
-
示例:
注:所有的压缩命令都可以同时压缩多个文件为一个压缩包。 -
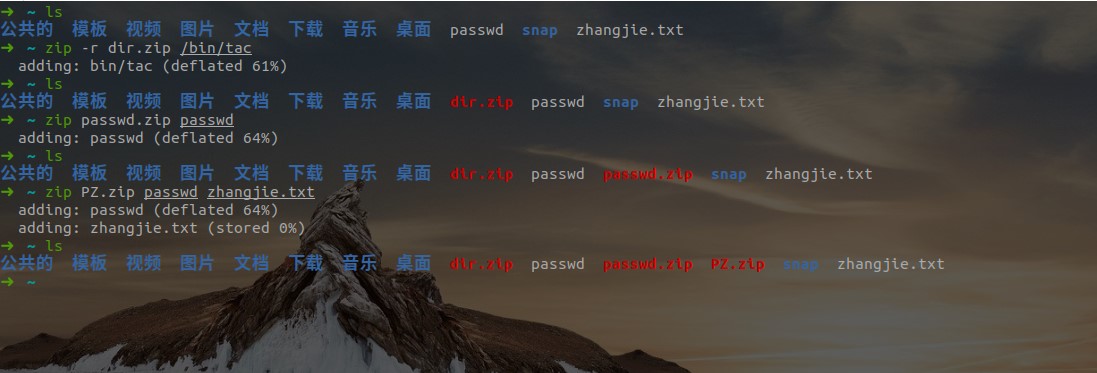
unzip解压zip文件
- 解压到当前目录:
unzip <filename.zip> - 解压到指定目录:
unzip <filename.zip> -d <目录> - 常用参数:
- 解压到当前目录:
| 参数 | 作用 |
|---|---|
| -l | 显 示压缩文件内所包含的文件。 |
| -t | 检 查压缩文件是否正确,但不解压。 |
| -v | 执行时显示详细的信息。 |
| -a | 对文本文件进行必要的字符转换。 |
| -b | 不 要对文本文件进行字符转换。 |
| -C | 压 缩文件中的文件名称区分大小写。 |
| -L | 将 压缩文件中的全部文件名改为小写。 |
| -o | 不 必先询问用户,unzip执 行后覆盖原有文件。 |
| -P<密码> | 使 用zip的密码选项。 |
| -q | 执 行时不显示任何信息。 |
| -d<目录> | 指 定文件解压缩后所要存储的目录。 |
| -x<文件> | 指 定不要处理.zip压 缩文件中的哪些文件。 |
-
示例:
-
tar打包工具
- 首先要弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件。。
- tar 原本只是一个打包工具,只是同时还是实现了对 7z、gzip、xz、bzip2 等工具的支持,这些压缩工具本身只能实现对文件或目录(单独压缩目录中的文件)的压缩,没有实现对文件的打包压缩。
- 基本命令格式:
tar(参数)(指定要打包的文件或目录列表) - 常用参数:
| 参数 | 说明 |
|---|---|
| -A或–catenate | 新增文件到以存在的备份文件 |
| -B | 设置区块大小 |
| -c或–create | 建立新的备份文件 |
| -C <目录> | 这个选项用在解压缩,若要在特定目录解压缩,可以使用这个选项。 |
| -d | 记录文件的差别 |
| -x或–extract或–get | 从备份文件中还原文件 |
| -t或–list | 列出备份文件的内容 |
| -z或–gzip或–ungzip | 通过gzip指令处理备份文件 |
| -Z或–compress或–uncompress | 通过compress指令处理备份文件 |
| -f<备份文件>或–file=<备份文件> | 指定备份文件 |
| -v或–verbose | 显示指令执行过程 |
| -r | 添加文件到已经压缩的文件 |
| -u | 添加改变了和现有的文件到已经存在的压缩文件 |
| -j | 支持bzip2解压文件 |
| -l | 文件系统边界设置 |
| -k | 保留原有文件不覆盖 |
| -m | 保留文件不被覆盖 |
| -w | 确认压缩文件的正确性 |
| -p或–same-permissions | 用原来的文件权限还原文件 |
| -P或–absolute-names | 文件名使用绝对名称,不移除文件名称前的“/”号 |
| -N <日期格式> 或 --newer=<日期时间> | 只将较指定日期更新的文件保存到备份文件里 |
| –exclude=<范本样式> | 排除符合范本样式的文件 |
- 示例:
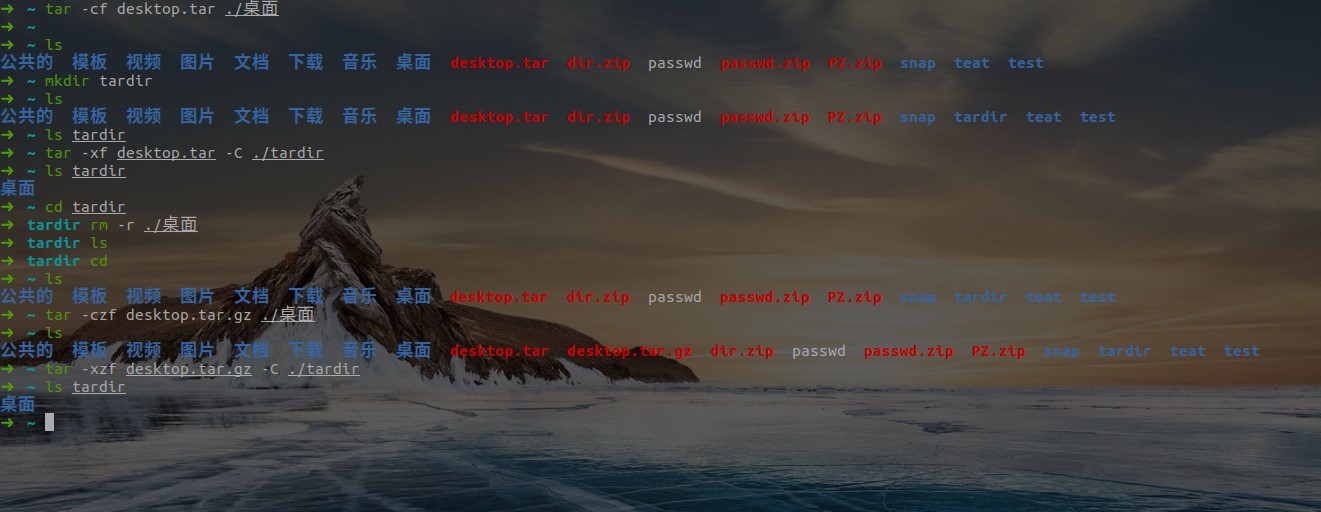
注:-c 表示创建一个 tar 包文件,-f 用于指定创建的文件名,注意文件名必须紧跟在 -f 参数之后,比如不能写成 tar -fc shiyanlou.tar,可以写成 tar -f shiyanlou.tar -c ~。我们只需要在创建 tar 文件的基础上添加 -z 参数,使用 gzip 来压缩文件。
八、数据流重定向
标准输出、输入及错误
- Linux 默认提供了三个特殊设备,用于终端的显示和输出,分别为stdin(标准输入,对应于你在终端的输入),stdout(标准输出,对应于终端的输出),stderr(标准错误输出,对应于终端的输出)。
| 文件描述符 | 设备文件 | 说明 |
|---|---|---|
| 0 | /dev/stdin | 标准输入 |
| 1 | /dev/stdout | 标准输出 |
| 2 | /dev/stderr | 标准错误输出 |
- 文件描述符:文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于 UNIX、Linux 这样的操作系统。
Linux输入重定向
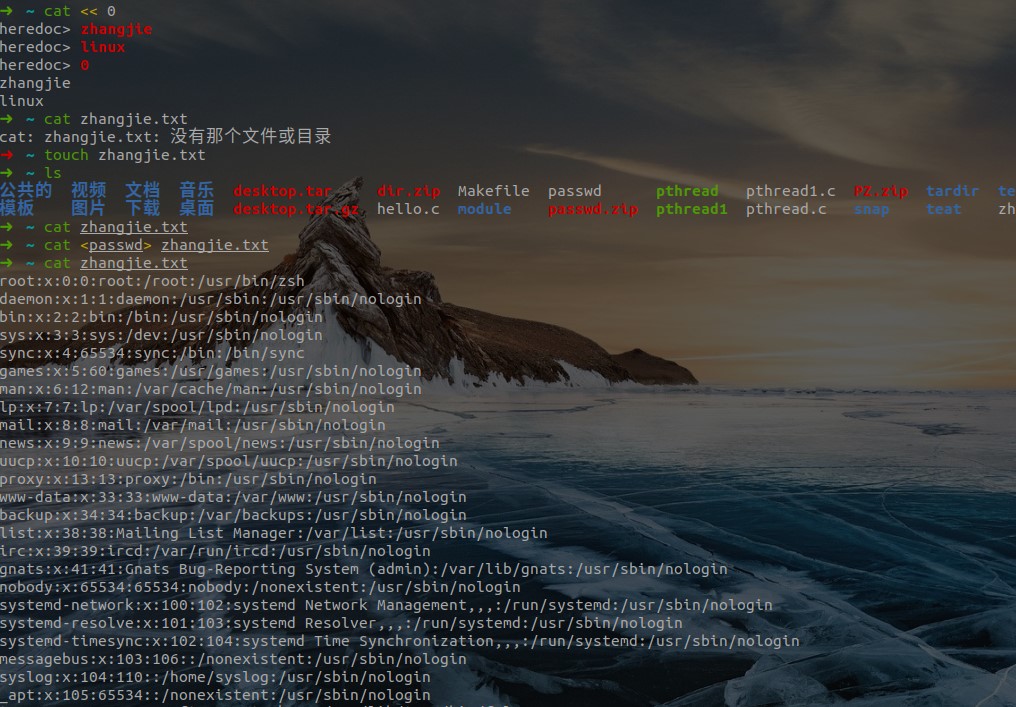
- 输入重定向中用到的符号及作用
| 命令符号格式 | 作用 |
|---|---|
| 命令 < 文件 | 将指定文件作为命令的输入设备 |
| 命令 << 分界符 | 表示从标准输入设备(键盘)中读入,直到遇到分界符才停止(读入的数据不包括分界符),这里的分界符其实就是自定义的字符串 |
| 命令 < 文件 1 > 文件 2 | 将文件 1 作为命令的输入设备,该命令的执行结果输出到文件 2 中。 |
- 示例:
Linux输出重定向
- 输出重定向用到的符号及作用
| 命令符号格式 | 作用 |
|---|---|
| 命令 > 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,会清空原有数据,再写入新数据。 |
| 命令 2> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,会清空原有数据,再写入新数据。 |
| 命令 >> 文件 | 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,新数据将写入到原有内容的后面。 |
| 命令 2>> 文件 | 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,新数据将写入到原有内容的后面。 |
| 命令 >> 文件 2>&1或者命令 &>> 文件 | 将标准输出或者错误输出写入到指定文件,如果该文件中已包含数据,新数据将写入到原有内容的后面。注意,第一种格式中,最后的 2>&1 是一体的,可以认为是固定写法。 |
- 示例:

九、基础底层知识
cpu
- 中央处理器(CPU,central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。CPU是计算机中负责读取指令,对指令译码并执行指令的核心部件。CPU的功效主要为处理指令、执行操作、控制时间、处理数据。
- 物理CPU:物理CPU是相对于虚拟CPU而言的概念,指实际存在的处理器,就是我们可以看的见,摸得着的CPU,就是插在主板上面的。
- 虚拟CPU:虚拟cpu是我们在做虚拟化时候,利用虚拟化技术,虚拟出来的CPU。如使用VMware时为虚拟机分配的CPU。
- CPU主要有3大组成部分:
- 运算器:算术逻辑运算单元(ALU,Arithmetic Logic Unit),负责执行所有的数学和逻辑工作。
- 控制器:控制单元(CU,Control Unit),控制计算机的所有其他部件,如输入输出设备以及存储器。
- 寄存器:存储单元,包括CPU片内缓存和寄存器组,是CPU中暂时存放数据的地方。
- CPU缓存:
- CPU缓存(Cache Memory)的出现是弥补CPU和主存(主内存,即内存条的)的速度差太大,用于提高效率的,有时可能也叫高速缓存。
- 高速缓存也分了很多层,一到四级,四级很少听但确实是有。一二级是各个核心独有的,三级缓存是所有核共享的。
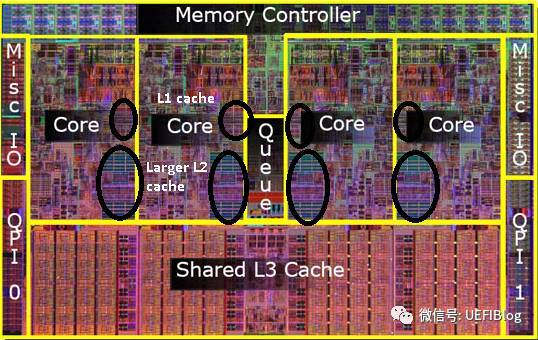
- CPU的个数:即CPU芯片个数。
- CPU工作原理图:
核心
- 核心(core,又称内核)是一个硬件术语,描述单个计算组件(管芯或芯片)中独立中央处理器的数量。
- CPU的核心数是指物理上,也就是硬件上存在着几个核心。比如,双核就是包括2个相对独立的CPU核心单元组,四核就包含4个相对独立的CPU核心单元组。
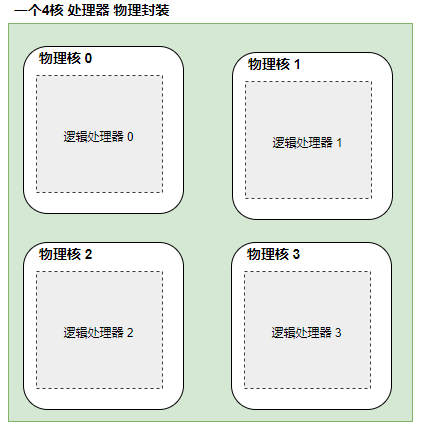
- 物理核:CPU中包含的物理内核(核心),比如多核CPU,单核CPU(老式CPU),这个多核或者单核已经集成在CPU内部。
- 逻辑核(逻辑CPU或虚拟核):用Intel的超线程技术(HT)将物理核虚拟而成的逻辑处理单元,现在大部分的主机的CPU都在使用HT技术,用一个物理核模拟两个虚拟核,即每个核两个线程。
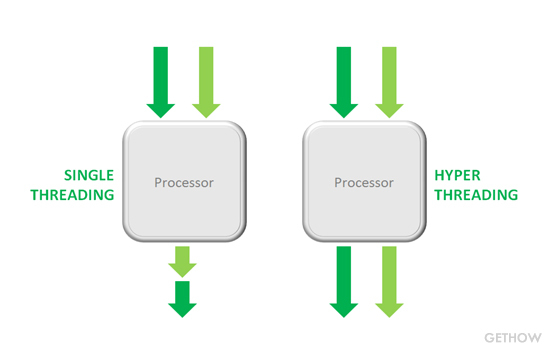
超线程技术
- 超线程技术把多线程处理器内部的两个逻辑内核模拟成两个物理芯片,让单个处理器就能使用线程级的并行计算,进而兼容多线程操作系统和软件。超线程技术充分利用空闲CPU资源,在相同时间内完成更多工作。
- 虽然采用超线程技术能够同时执行两个线程,当两个线程同时需要某个资源时,其中一个线程必须让出资源暂时挂起,直到这些资源空闲以后才能继续。因此,超线程的性能并不等于两个CPU的性能。
- 超线程技术图示:
程序、进程、线程
- 进程(process):进程是程序在一个数据集合上的一次执行过程,在早期的 UNIX、Linux 2.4 及更早的版本中,它是系统进行资源分配和调度的独立基本单位。
- 程序(procedure):程序是执行一系列有逻辑、有顺序结构的指令,帮我们达成某个结果。
- 进程与程序的区别:
- 简单来说,程序是为了完成某种任务而设计的软件,比如 vim 是程序。而进程就是运行中的程序。
- 进程的特性:
- 动态性:进程的实质是一次程序执行的过程,有创建、撤销等状态的变化。而程序是一个静态的实体。
- 并发性:进程可以做到在一个时间段内,有多个程序在运行中。程序只是静态的实体,所以不存在并发性。
- 独立性:进程可以独立分配资源,独立接受调度,独立地运行。
- 异步性:进程以不可预知的速度向前推进。
- 结构性:进程拥有代码段、数据段、PCB(进程控制块,进程存在的唯一标志)。也正是因为有结构性,进程才可以做到独立地运行。
- 进程的分类:
- 以进程的功能与服务的对象来分:
- 用户进程:通过执行用户程序、应用程序或称之为内核之外的系统程序而产生的进程,此类进程可以在用户的控制下运行或关闭。
- 系统进程:通过执行系统内核程序而产生的进程,比如可以执行内存资源分配和进程切换等相对底层的工作;而且该进程的运行不受用户的干预,即使是 root 用户也不能干预系统进程的运行。
- 以应用程序的服务类型来分:
- 交互进程:由一个 shell 终端启动的进程,在执行过程中,需要与用户进行交互操作,可以运行于前台,也可以运行在后台。
- 批处理进程:该进程是一个进程集合,负责按顺序启动其他的进程。
- 守护进程:守护进程是一直运行的一种进程,在 Linux 系统启动时启动,在系统关闭时终止。它们独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件。
- 以进程的功能与服务的对象来分:
- 进程的衍生
- 两个系统调用函数:
fork()是一个系统调用(system call),它的主要作用就是为当前的进程创建一个新的进程,这个新的进程就是它的子进程,这个子进程除了父进程的返回值和 PID 以外其他的都一模一样,如进程的执行代码段,内存信息,文件描述,寄存器状态等等。exec()也是系统调用,作用是切换子进程中的执行程序也就是替换其从父进程复制过来的代码段与数据段。
- 子进程与父进程:子进程就是父进程通过系统调用 fork() 而产生的复制品,fork() 就是把父进程的 PCB 等进程的数据结构信息直接复制过来,只是修改了 PID,所以一模一样,只有在执行 exec() 之后才会不同。
- 子进程的退出与回收:
- 当一个子进程要正常的终止运行时,或者该进程结束时它的主函数 main() 会执行 exit(n); 或者 return n,这里的返回值 n 是一个信号,系统会把这个 SIGCHLD 信号传给其父进程。
- 僵尸进程:在将要结束时的子进程代码执行部分已经结束执行了,系统的资源也基本归还给系统了,但若是其进程的进程控制块(PCB)仍驻留在内存中,而它的 PCB 还在,代表这个进程还存在(因为 PCB 就是进程存在的唯一标志,里面有 PID 等消息),并没有消亡,这样的进程称之为僵尸进程(Zombie)。
- 孤儿进程:另外如果父进程结束(非正常的结束),未能及时收回子进程,子进程仍在运行,这样的子进程称之为孤儿进程。在 Linux 系统中,孤儿进程一般会被 init 进程所“收养”,成为 init 的子进程。
- init进程:
- init 是用户进程的第一个进程也是所有用户进程的父进程或者祖先进程。就像一个树状图,而 init 进程就是这棵树的根,其他进程由根不断的发散,开枝散叶。
- 查看进程:
pstree命令查看进程树:
ps -afxo user,ppid,pid,pgid,command命令:其中 pid 就是该进程的一个唯一编号,ppid 就是该进程的父进程的 pid,command 表示的是该进程通过执行什么样的命令或者脚本而产生的。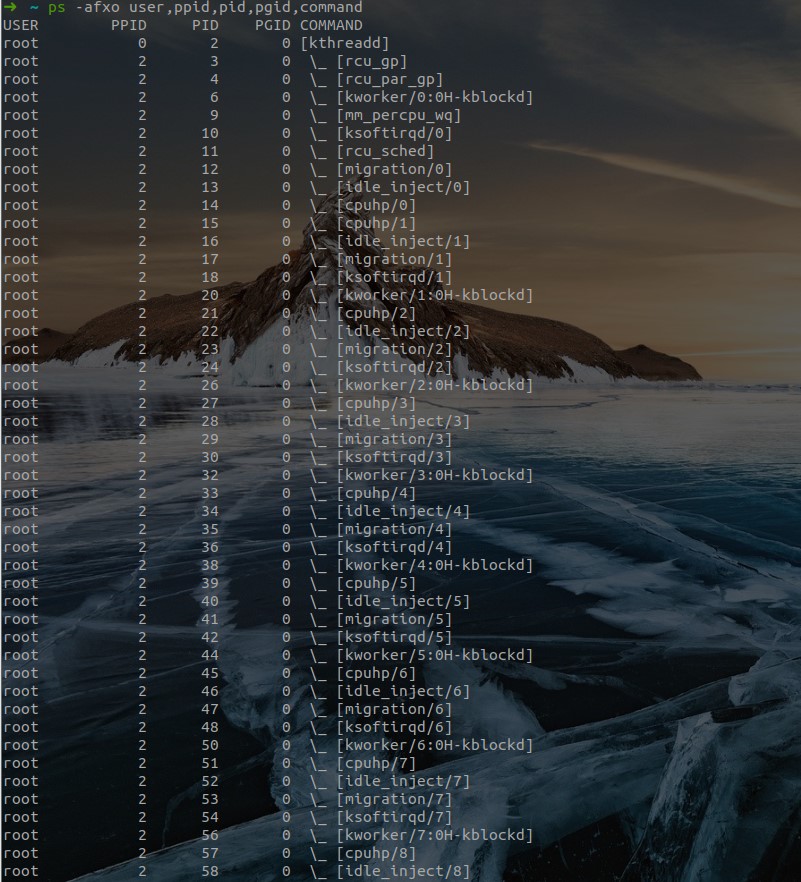
- 两个系统调用函数:
- 进程组与Sessions
- 进程组:
- 每一个进程都会是一个进程组的成员,而且这个进程组是唯一存在的,他们是依靠 PGID(process group ID)来区别的,而每当一个进程被创建的时候,它便会成为其父进程所在组中的一员。
- 一般情况,进程组的 PGID 等同于进程组的第一个成员的 PID,并且这样的进程称为该进程组的领导者,也就是领导进程,进程一般通过使用 getpgrp() 系统调用来寻找其所在组的 PGID,领导进程可以先终结,此时进程组依然存在,并持有相同的 PGID,直到进程组中最后一个进程终结。
- Session
- 与进程组类似,每当一个进程被创建的时候,它便会成为其父进程所在 Session 中的一员,每一个进程组都会在一个 Session 中,并且这个 Session 是唯一存在的。
- Session 主要是针对一个 tty(tty设备包括虚拟控制台,串口以及伪终端设备。tty是TeleTYpe的一个老缩写。) 建立,Session 中的每个进程都称为一个工作(job)。每个会话可以连接一个终端(control terminal)。当控制终端有输入输出时,都传递给该会话的前台进程组。Session 意义在于将多个 jobs 囊括在一个终端,并取其中的一个 job 作为前台,来直接接收该终端的输入输出以及终端信号。 其他 jobs 在后台运行。
- 前台(foreground)就是在终端中运行,能与你有交互的。
- 后台(background)就是在终端中运行,但是你并不能与其任何的交互,也不会显示其执行的过程。
- 进程组:
- 进程工作管理
- 我们都知道当一个进程在前台运作时我们可以用
ctrl + c来终止它,但是若是在后台的话就不行了。我们可以通过&这个符号,让我们的命令在后台中运行。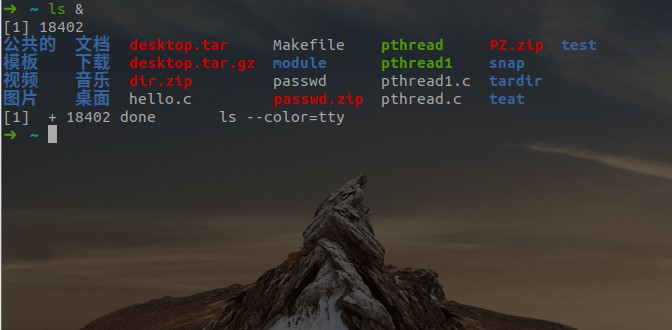 图中所显示的 [1] 18402分别是该 job 的 job number 与该进程的 PID,而最后一行的 Done 表示该命令已经在后台执行完毕。
图中所显示的 [1] 18402分别是该 job 的 job number 与该进程的 PID,而最后一行的 Done 表示该命令已经在后台执行完毕。 - 我们还可以通过 ctrl + z 使我们的当前工作停止并丢到后台中去。使用
jobs命令可以查看被停止并放置在后台的工作。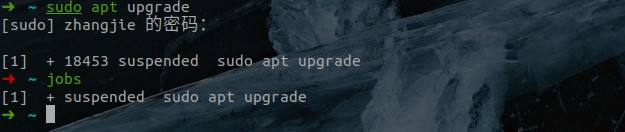 其中第一列显示的为被放置后台 job 的编号,而第二列的 + 表示最近(刚刚、最后)被放置后台的 job,同时也表示预设的工作,也就是若是有什么针对后台 job 的操作,首先对预设的 job,- 表示倒数第二(也就是在预设之前的一个)被放置后台的工作,倒数第三个(再之前的)以后都不会有这样的符号修饰,第三列表示它们的状态,而最后一列表示该进程执行的命令
其中第一列显示的为被放置后台 job 的编号,而第二列的 + 表示最近(刚刚、最后)被放置后台的 job,同时也表示预设的工作,也就是若是有什么针对后台 job 的操作,首先对预设的 job,- 表示倒数第二(也就是在预设之前的一个)被放置后台的工作,倒数第三个(再之前的)以后都不会有这样的符号修饰,第三列表示它们的状态,而最后一列表示该进程执行的命令 - 通过
fg %jobnumber(fg后面不加参数提取预设工作,加参数提取指定工作的编号将后台的工作拿到前台来。)
- 通过
bg %jobnumber可以将工作放入后台运作。 kill命令:- 删除一个工作,或者重启等等。
- 使用格式:
kill -signal %jobnumber - 注意:
- 若是在使用 kill +信号值然后直接加 pid,你将会对 pid 对应的进程进行操作。
- 若是在使用 kill+信号值然后 %jobnumber,这时所操作的对象是 job,这个数字就是就当前 bash 中后台的运行的 job 的 ID。
- 其中常用的有这些信号值
- 我们都知道当一个进程在前台运作时我们可以用
| 信号值 | 作用 |
|---|---|
| -1 | 重新读取参数运行,类似与 restart |
| -2 | 如同 ctrl+c 的操作退出 |
| -9 | 强制终止该任务 |
| -15 | 正常的方式终止该任务 |

- 进程查看
top工具:- top 工具是我们常用的一个查看工具,能实时的查看我们系统的一些关键信息的变化。
- top 是一个在前台执行的程序,所以执行后便进入到这样的一个交互界面,正是因为交互界面我们才可以实时的获取到系统与进程的信息。在交互界面中我们可以通过一些指令来操作和筛选。
- 常用交互命令:
| 常用交互命令 | 解释 |
|---|---|
| q | 退出程序 |
| I | 切换显示平均负载和启动时间的信息 |
| P | 根据 CPU 使用百分比大小进行排序 |
| M | 根据驻留内存大小进行排序 |
| i | 忽略闲置和僵死的进程,这是一个开关式命令 |
| k | 终止一个进程,系统提示输入 PID 及发送的信号值。一般终止进程用 15 信号,不能正常结束则使用 9 信号。安全模式下该命令被屏蔽。 |
- 示例:
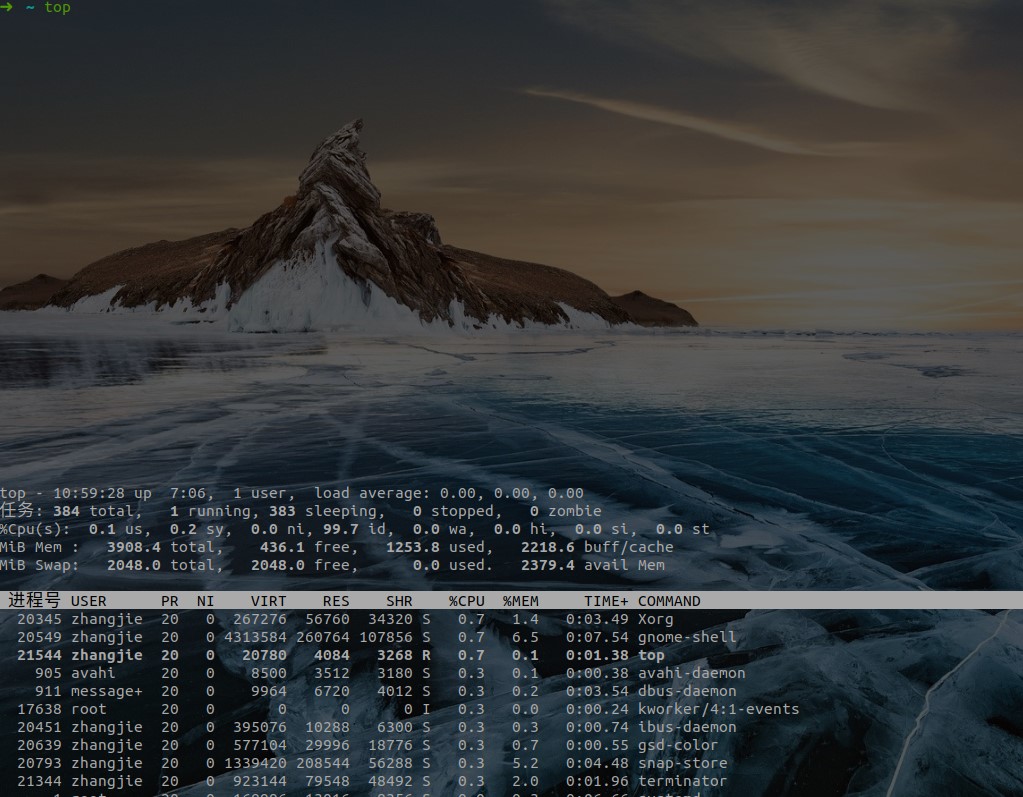
- top 显示的第一排,
| 内容 | 解释 |
|---|---|
| top | 表示当前程序的名称 |
| 10:59:28 | 表示当前的系统的时间 |
| up 7 :06 | 表示该机器已经启动了多长时间 |
| 1 user | 表示当前系统中只有一个用户 |
| load average: 0.00,0.00,0.00 | 分别对应 1、5、15 分钟内 cpu 的平均负载 |
- top 的第二行数据,基本上第二行是进程的一个情况统计
| 内容 | 解释 |
|---|---|
| Tasks: 384 total | 进程总数 |
| 1 running | 1 个正在运行的进程数 |
| 383 sleeping | 383 个睡眠的进程数 |
| 0 stopped | 没有停止的进程数 |
| 0 zombie | 没有僵尸进程数 |
- top 的第三行数据,这一行基本上是 CPU 的一个使用情况的统计了
| 内容 | 解释 |
|---|---|
| Cpu(s): 0.1 us | 用户空间进程占用 CPU 百分比 |
| 0.2 sy | 内核空间运行占用 CPU 百分比 |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用 CPU 百分比 |
| 99.7 id | 空闲 CPU 百分比 |
| 0.0 wa | 等待输入输出的 CPU 时间百分比 |
| 0.0 hi | 硬中断(Hardware IRQ)占用 CPU 的百分比 |
| 0.0 si | 软中断(Software IRQ)占用 CPU 的百分比 |
| 0.0 st | (Steal time) 是 hypervisor 等虚拟服务中,虚拟 CPU 等待实际 CPU 的时间的百分比 |
- top 的第四行数据,这一行基本上是内存的一个使用情况的统计了:
| 内容 | 解释 |
|---|---|
| 3908.4 total | 物理内存总量 |
| 436.1 free | 空闲内存总量 |
| 1253.8 used | 使用的物理内存总量 |
| 2218.6 buff/cache | 用作内核缓存的内存量 |
- top 的第五行数据,这一行基本上是交换区的一个使用情况的统计了
| 内容 | 解释 |
|---|---|
| 2048.0 total | 交换区总量 |
| 2048.0 free | 空闲交换区总量 |
| 0.0 used | 使用的交换区总量 |
| 2379.4 avail Mem | 缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖 |
- 再下面就是进程的一个情况了
| 列名 | 解释 |
|---|---|
| PID/进程号 | 进程 id |
| USER | 该进程的所属用户 |
| PR | 该进程执行的优先级 priority 值 |
| NI | 该进程的 nice 值 |
| VIRT | 该进程任务所使用的虚拟内存的总数 |
| RES | 该进程所使用的物理内存数,也称之为驻留内存数 |
| SHR | 该进程共享内存的大小 |
| S | 该进程进程的状态: S=sleep R=running Z=zombie |
| %CPU | 该进程 CPU 的利用率 |
| %MEM | 该进程内存的利用率 |
| TIME+ | 该进程活跃的总时间 |
| COMMAND | 该进程运行的名字 |
-
注意:
- NICE 值叫做静态优先级,是用户空间的一个优先级值,其取值范围是-20 至 19。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。nice 值中的 -20 到 19,中 -20 优先级最高, 0 是默认的值,而 19 优先级最低。
- PR 值表示 Priority 值叫动态优先级,是进程在内核中实际的优先级值,进程优先级的取值范围是通过一个宏定义的,这个宏的名称是 MAX_PRIO,它的值为 140。Linux 实际上实现了 140 个优先级范围,取值范围是从 0-139,这个值越小,优先级越高。而这其中的 0 - 99 是实时进程的值,而 100 - 139 是给用户的。其中 PR 中的 100 to 139 值部分有这么一个对应 PR = 20 + (-20 to +19),这里的 -20 to +19 便是 nice 值,所以说两个虽然都是优先级,而且有千丝万缕的关系,但是他们的值,他们的作用范围并不相同
- VIRT 任务所使用的虚拟内存的总数,其中包含所有的代码,数据,共享库和被换出 swap 空间的页面等所占据空间的总数
-
线程:线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。因为线程中几乎不包含系统资源,所以执行更快、更有效率。
-
进程与线程对比:
| 对比 | 进程 | 线程 |
|---|---|---|
| 定义 | 进程是程序运行的一个实体的运行过程,是系统进行资源分配和调配的一个独立单位 | 线程是进程运行和执行的最小调度单位 |
| 系统开销 | 创建撤销切换开销大,资源要重新分配和收回 | 仅保存少量寄存器的内容,开销小,在进程的地址空间执行代码 |
| 拥有资源 | 资源拥有的基本单位 | 基本上不占资源,仅有不可少的资源(程序计数器,一组寄存器和栈) |
| 调度 | 资源分配的基本单位 | 独立调度分配的单位 |
| 安全性 | 进程间相互独立,互不影响 | 线程共享一个进程下面的资源,可以互相通信和影响 |
| 地址空间 | 系统赋予的独立的内存地址空间 | 由相关堆栈寄存器和和线程控制表TCB组成,寄存器可被用来存储线程内的局部变量 |
- 串行,并发与并行
- 串行
- 多个任务,执行时一个执行完再执行另一个。
- 比喻:吃完饭再看视频。
- 并发
- 多个线程在单个核心运行,同一时间一个线程运行,系统不停切换线程,看起来像同时运行,实际上是线程不停切换。
- 比喻: 一会跑去厨房吃饭,一会跑去客厅看视频。
- 并行
- 每个线程分配给独立的核心,线程同时运行。
- 比喻:一边吃饭一边看视频。
- 串行
十、多线程编程
多线程编程基本概念
进程是资源管理的基本单元,而线程是系统调度的基本单元,线程是操作系统能够进行调度运算的最小单位,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。一个进程在某一个时刻只能做一件事情,有了多个控制线程以后,在程序的设计成在某一个时刻能够做不止一件事,每个线程处理独自的任务。
linux操作系统使用符合POSIX线程作为系统标准线程,该POSIX线程标准定义了一整套操作线程的API。
进程的状态
- 进程从创建到运行结束,经历的全部过程,称为进程的生命周期。在生命周期的不同阶段,进程会呈现不同的状态。
| 状态 | 含义 |
|---|---|
| 创建状态 | 正在创建 |
| 就绪 | 刚刚创建好,还没运行过 |
| 内核状态 | 运行中 |
| 用户状态 | 暂停中 |
| 睡眠 | 运行中的进程因为某些需求得不到满足而进入等待状态 |
| 唤醒 | 睡眠中的进程,正在被唤醒 |
| 被抢占 | 运行期间,CPU 被另一个进程抢占 |
| 僵死状态 | 进程已经结束,但内存空间等占用的资源还未释放,被称为僵尸进程 |
线程标识
- 与进程有一个ID一样,每个线程有一个线程ID,所不同的是,进程ID在整个系统中是唯一的,而线程是依附于进程的,其线程ID只有在所属的进程中才有意义。线程ID用
pthread_t表示。
//pthread_self直接返回调用线程的ID
#include <pthread.h>
pthread_t pthread_self(void);//pthread_equal如果t1和t2所指定的线程ID相同,返回0;否则返回非0值。
include <pthread.h>
int pthread_equal(pthread_t t1, pthread_t t2);线程创建
- 一个线程的生命周期起始于它被创建的那一刻。
//pthread_creat创建线程
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
参数说明:
thread(输出参数),线程的标识符,需要说明的是这个参数并不是用户确定的,用户只需声明一个pthread_t类型的变量,并将一个指向该变量的指针作为实参传递给pthread_create函数,函数在创建线程时会将新线程的线程标识符放到这个变量中。
start_routine(输入参数),新建线程的入口函数;
arg(输入参数),传递给新线程入口函数的参数;
attr(输入参数),指定新建线程的属性,如线程栈大小等;如果值为NULL,表示使用系统默认属性。
函数返回值:
成功,返回0;
失败,返回相关错误码。线程属性:
- pthread_create函数的第二个参数类型定义如下:
typedef struct {
int detachstate; //线程的分离状态
int schedpolicy; //线程的调度策略
struct sched_param schedparam; //线程的调度参数
int inheritsched; //线程的继承性
int scope; //线程的作用域
size_t guardsize;
int stackaddr_set; //线程堆栈的位置,通常来说这是线程堆栈的最低位置
void *stackaddr;
size_t stacksize; //线程堆栈的大小
}pthread_attr_t;- 线程的初始化与销毁: 在使用一个线程属性对象之前,必须对其进行初始化,pthread_attr_init函数用于完成初始化;在使用完一个线程属性对象后,必须对其进行销毁,pthread_attr_destroy函数用于完成销毁工作。
#include <pthread.h>
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_destroy(pthread_attr_t *attr);线程终止
线程的终止分两种形式:被动终止和主动终止。
- 被动终止的两种方式
- 线程所在进程终止,任意线程执行exit、_Exit或者_exit函数,都会导致进程终止,从而导致依附于该进程的所有线程终止。
- 其他线程调用pthread_cancel请求取消该线程。
- 主动终止的两种方式:
- 在线程的入口函数中执行return语句,main函数(主线程入口函数)执行return语句会导致进程终止,从而导致依附于该进程的所有线程终止。
- 线程调用pthread_exit函数,main函数(主线程入口函数)调用pthread_exit函数, 主线程终止,但如果该进程内还有其他线程存在,进程会继续存在,进程内其他线程继续运行。
- 线程终止函数:
//pthread_exit终止线程
#include <pthread.h>
void pthread_exit(void *retval);线程终止的管理
- 线程的连接:一个线程的终止对于另外一个线程而言是一种异步的事件,有时我们想等待某个ID的线程终止了再去执行某些操作,pthread_join函数为我们提供了这种功能,该功能称为线程的连接。当线程X连接线程Y时,如果线程Y仍在运行,则线程X会阻塞直到线程Y终止;如果线程Y在被连接之前已经终止了,那么线程X的连接调用会立即返回。连接线程其实还有另外一层意义,一个线程终止后,如果没有人对它进行连接,那么该终止线程占用的资源,系统将无法回收,而该终止线程也会成为僵尸线程。因此,当我们去连接某个线程时,其实也是在告诉系统该终止线程的资源可以回收了。
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
参数说明:
thread(输入参数),指定我们希望等待的线程
retval(输出参数),我们等待的线程终止时的返回值,就是在线程入口函数中return的值或者调用pthread_exit函数的参数
返回值:
成功时,返回0
错误时,返回正数错误码- 线程的分离:有时我们并不在乎某个线程是不是已经终止了,我们只是希望如果某个线程终止了,系统能自动回收掉该终止线程所占用的资源。pthread_detach函数为我们提供了这个功能,该功能称为线程的分离。默认情况下,一个线程终止了,是需要在被连接后系统才能回收其占有的资源的。如果我们调用pthread_detach函数去分离某个线程,那么该线程终止后系统将自动回收其资源。
#include <pthread.h>
int pthread_detach(pthread_t thread);
参数说明:
thread(输入参数),指定我们希望分离的线程。
返回值:
成功时,返回0
错误时,返回正数错误码简单的多线程打印实际操作
- 代码:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>//sleep函数在此头文件中
void *mythread1(void)
{
int i;
for(i = 0; i < 10; i++)
{
printf("This is the 1st pthread,created by zhangjie!\n");
sleep(1);
}
}
void *mythread2(void)
{
int i;
for(i = 0; i < 10; i++)
{
printf("This is the 2st pthread,created by zhangjie!\n");
sleep(1);
}
}
int main(int argc, const char *argv[])
{
int i = 0;
int ret = 0;
pthread_t id1,id2;
ret = pthread_create(&id1, NULL, (void *)mythread1,NULL);
if(ret)
{
printf("Create pthread error!\n");
return 1;
}
ret = pthread_create(&id2, NULL, (void *)mythread2,NULL);
if(ret)
{
printf("Create pthread error!\n");
return 1;
}
pthread_join(id1,NULL);
pthread_join(id2,NULL);
return 0;
}- 操作结果:
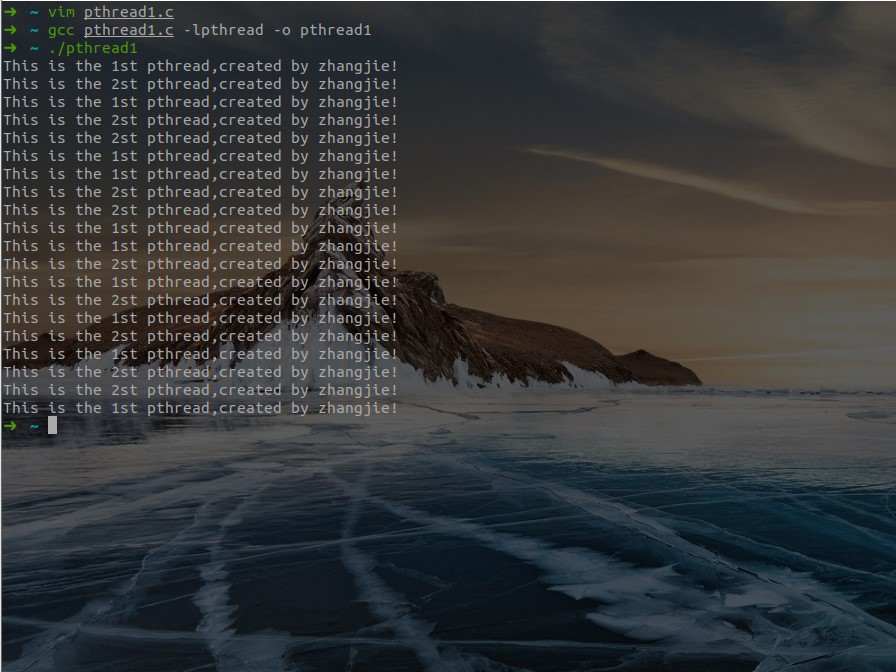
注意:因为pthread的库不是linux系统的库,所以在进行编译的时候要加上-lpthread,否则编译不过。
线程间同步机制
如果变量时只读的,多个线程同时读取该变量不会有一致性问题,但是,当一个线程可以修改的变量,其他线程也可以读取或者修改的时候,我们就需要对这些线程进行同步,确保它们在访问变量的存储内容时不会访问到无效的值。
互斥锁
- 互斥量概念:多线程程序中可能会存在数据不一致的情况,那么如何保证数据一致呢?可以考虑同一时间只有一个线程访问数据。互斥量(mutex)就是一把锁。多个线程只有一把锁一个钥匙,谁上的锁就只有谁能开锁。当一个线程要访问一个共享变量时,先用锁把变量锁住,然后再操作,操作完了之后再释放掉锁,完成。当另一个线程也要访问这个变量时,发现这个变量被锁住了,无法访问,它就会一直等待,直到锁没了,它再给这个变量上个锁,然后使用,使用完了释放锁,以此进行。这个即使有多个线程同时访问这个变量,也好象是对这个变量的操作是顺序进行的。
- 互斥量用pthread_mutex_t数据类型表示。
- 互斥锁的使用:
- 初始化锁:在Linux下,线程的互斥量数据类型是pthread_mutex_t。在使用前,要对它进行初始化。
- 静态分配:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; - 动态分配:
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutex_attr_t *mutexattr);
- 静态分配:
- 加锁:对共享资源的访问,要对互斥量进行加锁,如果互斥量已经上了锁,调用线程会阻塞,直到互斥量被解锁。
int pthread_mutex_lock(pthread_mutex *mutex);对互斥量mutex进行加锁,如果互斥量已经上锁,调用线程将一直阻塞直到互斥量被解锁。int pthread_mutex_trylock(pthread_mutex_t *mutex);尝试对互斥量mutex进行加锁,如果互斥量mutex处于未被锁住的状态,则将锁住该互斥量并返回0。如果互斥量mutex处于锁住的状态,则不能锁住该互斥量并返回EBUSY。
- 解锁:在完成了对共享资源的访问后,要对互斥量进行解锁。
int pthread_mutex_unlock(pthread_mutex_t *mutex);
- 销毁锁:锁在是使用完成后,需要进行销毁以释放资源。
int pthread_mutex_destroy(pthread_mutex *mutex);
- 初始化锁:在Linux下,线程的互斥量数据类型是pthread_mutex_t。在使用前,要对它进行初始化。
- 互斥量的死锁:
- 一个线程需要访问两个或者更多不同的共享资源,而每个资源又有不同的互斥量管理。当超过一个线程加锁同一组互斥量时,就可能发生死锁。死锁就是指多个线程/进程因竞争资源而造成的一种僵局(相互等待),若无外力作用,这些进程都将无法向前推进。
- 死锁的处理策略:
- 预防死锁:破坏死锁产生的四个条件:互斥条件、不剥夺条件、请求和保持条件以及循环等待条件。
- 避免死锁:在每次进行资源分配前,应该计算此次分配资源的安全性,如果此次资源分配不会导致系统进入不安全状态,那么将资源分配给进程,否则等待。
- 检测死锁:检测到死锁后通过资源剥夺、撤销进程、进程回退等方法解除死锁。
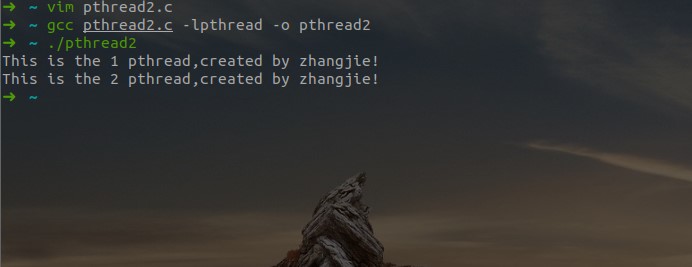
- 互斥锁在多线程打印中的应用示例:
- 代码:
#include <stdio.h> #include <pthread.h> #include <unistd.h>//sleep函数在此头文件中 static pthread_mutex_t g_mutex_lock; static int g_count = 0; void *mythread1(void) { pthread_mutex_lock(&g_mutex_lock);//加锁 g_count++; printf("This is the %d pthread,created by zhangjie!\n",g_count); pthread_mutex_unlock(&g_mutex_lock);//解锁 sleep(1); } void *mythread2(void) { pthread_mutex_lock(&g_mutex_lock); g_count++; printf("This is the %d pthread,created by zhangjie!\n",g_count); pthread_mutex_unlock(&g_mutex_lock);//解锁 sleep(1); } int main(int argc, const char *argv[]) { int i = 0; int ret = 0; pthread_t id1,id2; ret = pthread_create(&id1, NULL, (void *)mythread1,NULL); if(ret) { printf("Create pthread error!\n"); return 1; } ret = pthread_create(&id2, NULL, (void *)mythread2,NULL); if(ret) { printf("Create pthread error!\n"); return 1; } pthread_join(id1,NULL); pthread_join(id2,NULL); pthread_mutex_destroy(&g_mutex_lock);//销毁锁 return 0; }- 操作结果:
- 双线程交替打印AB
代码:
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
#include <time.h>
void* Print(void *Message)
{
for(;;){
int pauseTime = rand() % 6;
sleep(pauseTime);
printf("%c\n", (char)Message);
}
return NULL;
}
int main()
{
pthread_t thread_1, thread_2;
srand(time(0));
pthread_create(&thread_1, NULL, Print, (void*)'A');
pthread_create(&thread_2, NULL, Print, (void*)'B');
pthread_join(thread_1, NULL);
pthread_join(thread_2, NULL);
return 0;
}
十一、Linux内核
Linux内核的简介
- 概述:Linux内核是Linux操作系统一部分。对下,它管理系统的所有硬件设备;对上,它通过系统调用,向Library Routine(例如C库)或者其它应用程序提供接口。
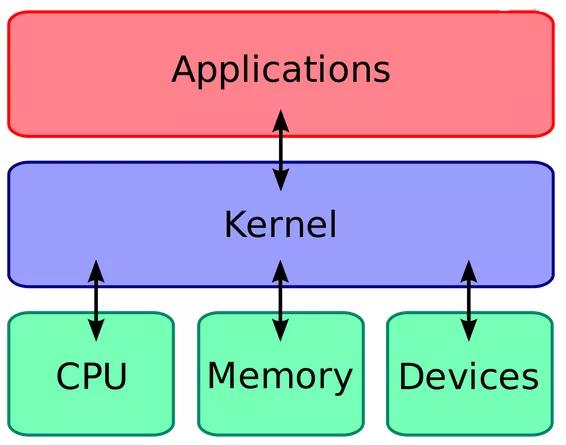
- Linux内核的任务:
- 从技术层面讲,内核是硬件与软件之间的一个中间层。作用是将应用层序的请求传递给硬件,并充当底层驱动程序,对系统中的各种设备和组件进行寻址。
- 从应用程序的层面讲,应用程序与硬件没有联系,只与内核有联系,内核是应用程序知道的层次中的最底层。在实际工作中内核抽象了相关细节。
- 内核是一个资源管理程序。负责将可用的共享资源(CPU时间、磁盘空间、网络连接等)分配得到各个系统进程。
- 内核就像一个库,提供了一组面向系统的命令。系统调用对于应用程序来说,就像调用普通函数一样。
- 内核的实现策略:
- 微内核:最基本的功能由中央内核(微内核)实现。所有其他的功能都委托给一些独立进程,这些进程通过明确定义的通信接口与中心内核通信。
- 宏内核:内核的所有代码,包括子系统(如内存管理、文件管理、设备驱动程序)都打包到一个文件中。内核中的每一个函数都可以访问到内核中所有其他部分。支持模块的动态装卸(裁剪)。Linux内核就是基于这个策略实现的。
- Linux内核的组成部分:
- kernel:内核核心,一般为bzImage格式,通常位于/boot目录,名称为vmlinuz-VERSION-release;当系统启动之后该文件就不在使用,因为已经加载到内存,放置/boot下方便管理。
- kernel object:内核模块,一般放置于/lib/modules/VERSION-release/;内核模块与内核核心版本一定要严格匹配。
Linux内核的整体架构
- 整体架构:

- 子系统简介:根据内核的核心功能,Linux内核提出了5个子系统
- Process Scheduler:也称作进程管理、进程调度。负责管理CPU资源,以便让各个进程可以以尽量公平的方式访问CPU。
- Memory Manager:内存管理。负责管理Memory(内存)资源,以便让各个进程可以安全地共享机器的内存资源。另外,内存管理会提供虚拟内存的机制,该机制可以让进程使用多于系统可用Memory的内存,不用的内存会通过文件系统保存在外部非易失存储器中,需要使用的时候,再取回到内存中。
- VFS(Virtual File System):虚拟文件系统。Linux内核将不同功能的外部设备,例如Disk设备(硬盘、磁盘、NAND Flash、Nor Flash等)、输入输出设备、显示设备等等,抽象为可以通过统一的文件操作接口(open、close、read、write等)来访问。这就是Linux系统“一切皆是文件”的体现。
- Network:网络子系统。负责管理系统的网络设备,并实现多种多样的网络标准。
- IPC(Inter-Process Communication),进程间通信。IPC不管理任何的硬件,它主要负责Linux系统中进程之间的通信。
Linux内核模块
Linux内核的模块化设计
- 内核模块化简介:
- 为了改善单一体系结构的可扩展性、可维护性等,Linux操作系统使用了一种全新的内核模块机制。用户可以根据需要,在不需要对内核重新编译的情况下,模块能动态地装入内核或从内核移出。
- 模块是在内核空间运行的程序,实际上是一种目标对象文件,没有链接,不能独立运行,但是其代码可以在运行时链接到系统中作为内核的一部分运行或从内核中取下,从而可以动态扩充内核的功能。这种目标代码通常由一组函数和数据结构组成,用来实现一种文件系统,一个驱动程序,或其它内核上层的功能。模块机制的完整叫法应该是动态可加载内核模块(Loadable Kernel Module)或 LKM,一般就简称为模块。
- 内核模块化的特点:
- 使得内核更加紧凑和灵活。
- 修改内核时,不必全部重新编译整个内核,可节省不少时间,避免人工操作的错误。系统中如果需要使用新模块,只要编译相应的模块然后使用特定用户空间的程序将模块插入即可。
- 模块可以不依赖于某个固定的硬件平台。
- 模块的目标代码一旦被链接到内核,它的作用和静态链接的内核目标代码完全等价。 所以,当调用模块的函数时,无须显式的消息传递。
- Linux模块的组成部分:
- 模块加载函数(必须):当通过insmod命令加载内核模块时,模块的加载函数会自动被内核执行,完成本模块相关初始化工作。
- 模块卸载函数(必须):当通过rmmod命令卸载模块时,模块的卸载函数会自动被内核执行,完成与模块加载函数相反的功能。
- 模块许可证声明(必须):模块许可证(LICENCE)声明描述内核模块的许可权限,如果不声明LICENCE,模块被加载时将收到内核被污染的警告。大多数情况下,内核模块应遵循GPL 兼容许可权。Linux2.6 内核模块最常见的是以MODULE_LICENSE(“Dual BSD/GPL”)语句声明模块采用BSD/GPL 双LICENSE。
- 模块参数(可选):模块参数是模块被加载的时候可以被传递给他的值,它本身对应模块内部的全局变量。
- 模块导出符号(可选):内核模块可以导出符号(symbol,对应于函数或变量),这样其他模块可以使用本模块中的变量或函数。
- 模块作者等信息声明(可选)。
- 内核模块与普通应用程序的比较:
| C语言普通应用程序 | 模块程序 | |
|---|---|---|
| 入口 | main() | init_module() |
| 出口 | 无 | cleanup_module() |
| 编译 | gcc –c | 编制专用Makefile,并调用gcc |
| 连接 | gcc | insmod |
| 运行 | 直接运行 | insmod |
| 调试 | gdb | kdbug, kdb, kgdb等内核调试工具 |
内核模块实现
- 内核模块的数据结构
- 每一个内核模块在内核中都对应一个数据结构module,所有的模块通过一个链表维护。
- 部分成员例举(跟模块有关的数据结构存放在include/linux/module.h):
struct module { enum module_state state; //状态 /* Member of list of modules */ struct list_head list; //所有的模块构成双链表,包头为全局变量modules /* Unique handle for this module */ char name[MODULE_NAME_LEN]; //模块名字,唯一,一般存储去掉.ko的部分 /* Sysfs stuff. */ struct module_kobject mkobj; struct module_attribute *modinfo_attrs; const char *version; const char *srcversion; struct kobject *holders_dir; /* Exported symbols *//**/ const struct kernel_symbol *syms; //导出符号信息,指向一个kernel_symbol的数组,有num_syms个表项。 const unsigned long *crcs; //同样有num_syms个表项,不过存储的是符号的校验和 unsigned int num_syms; /* Kernel parameters. */ struct kernel_param *kp; unsigned int num_kp; /* GPL-only exported symbols. */ unsigned int num_gpl_syms;/ /具体意义同上面符号,但是这里只适用于GPL兼容的模块 const struct kernel_symbol *gpl_syms; const unsigned long *gpl_crcs; #ifdef CONFIG_UNUSED_SYMBOLS /* unused exported symbols. */ const struct kernel_symbol *unused_syms; const unsigned long *unused_crcs; unsigned int num_unused_syms; /* GPL-only, unused exported symbols. */ unsigned int num_unused_gpl_syms; const struct kernel_symbol *unused_gpl_syms; const unsigned long *unused_gpl_crcs; #endif #ifdef CONFIG_MODULE_SIG /* Signature was verified. */ bool sig_ok; #endif /* symbols that will be GPL-only in the near future. */ const struct kernel_symbol *gpl_future_syms; const unsigned long *gpl_future_crcs; unsigned int num_gpl_future_syms; /* Exception table */ unsigned int num_exentries; struct exception_table_entry *extable; /* Startup function. */ int (*init)(void); //模块初始化函数指针 /* If this is non-NULL, vfree after init() returns */ void *module_init; /如果该函数不为空,则init结束后就可以调用进行适当释放 /* Here is the actual code + data, vfree'd on unload. */ void *module_core; //核心数据和代码部分,在卸载的时候会调用 /* Here are the sizes of the init and core sections */ unsigned int init_size, core_size; //对应于上面的init和core函数,决定各自占用的大小 /* The size of the executable code in each section. */ unsigned int init_text_size, core_text_size; /* Size of RO sections of the module (text+rodata) */ unsigned int init_ro_size, core_ro_size; ...... #ifdef CONFIG_MODULE_UNLOAD /*模块间的依赖关系记录*/ /* What modules depend on me? */ struct list_head source_list; /* What modules do I depend on? */ struct list_head target_list; /* Who is waiting for us to be unloaded */ struct task_struct *waiter; //等待队列,记录那些进程等待模块被卸载 /* Destruction function. */ void (*exit)(void); //卸载退出函数,模块中定义的exit函数 ...... }; - 内核符号表:
- 内核符号表是一个用来存放所有模块可以访问的那些符号以及相应地址的特殊的表。模块的连接就是将模块插入到内核的过程。模块所声明的任何全局符号都成为内核符号表的一部分。内核模块根据系统符号表从内核空间中获取符号的地址,从而确保在内核空间中正确地运行。
- 这是一个公开的符号表,我们可以从文件/proc/kallsyms中以文本的方式读取。在这个文件中存放数据地格式如下:
内存地址 属性 符号名称 【所属模块】
- 模块依赖:
- 内核符号表记录了所有模块可以访问的符号及相应地址。一个内核模块被装入后,它所声明的符号就会被记录到这个表里,而这些符号当然就可能会被其他模块所引用。这就引出了模块依赖这个问题。
- 一个模块A引用另一个模块B所导出的符号,我们就说模块B被模块A引用,或者说模块A装载到模块B的上面。如果要链接模块A,必须先要链接模块B。否则,模块B所导出的那些符号的引用就不可能被链接到模块A中。这种模块间的相互关系就叫做模块依赖。
- 模块间的依赖关系通过两个节点source_list和target_list记录,前者记录那些模块依赖于本模块,后者记录本模块依赖于那些模块。节点通过module_use记录,module_use如下(定义在include/linux/module.h中):
struct module_use { struct list_head source_list; struct list_head target_list; struct module *source, *target; }; - 内核描述:
- 每当内核需要使用这个模块提供的功能,就会到链表modules中寻找这个模块,并调用模块使用export修饰的功能函数。module中,成员state为模块当前的状态。它是一个枚举类型的变量,可取的值为MODULE_STATE_LIVE、MODULE_STATE_COMING、MODULE_STATE_GOING,分为当前正常使用中(存活状态)、模块当前正在被加载和模块当前正在被卸载三种状态。
- 当模块向内核加载时,insmod调用内核的模块加载函数,该函数在完成模块的部分创建工作后,将模块的状态置为MODULE_STATE_COMING。接着内核将调用内核模块初始化函数,并在完成所有的初始化工作之后(包括将模块加入模块注册表,调用模块本身的初始化函数),将模块状态设置为MODULE_STATE_LIVE。
- 当使用rmmod命令卸载模块时,内核将调用系统调用delete_module,并将模块的状态置为MODULE_STATE_GOING。
内核模块的基本操作
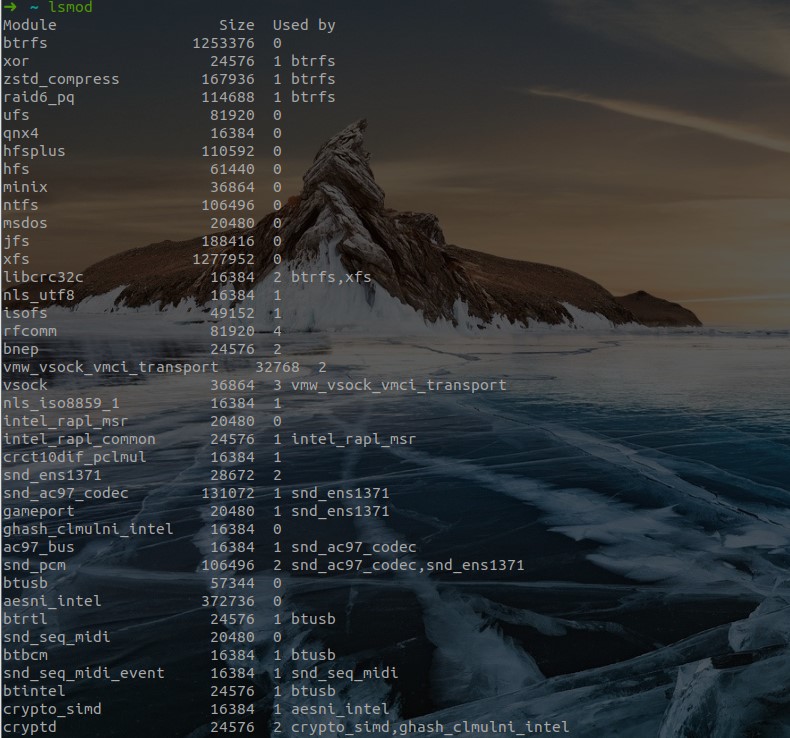
- 核心模块的观察
lsmod(list module)命令;- 使用 lsmod 之后,系统会显示出目前已经存在於核心当中的模块,显示的内容包括有:模块名称(Module);模块的大小(size);此模块是否被其他模块所使用 (Used by)。
- 核心模块的加载与移除:
insmod加载模块:格式insmod <modulename>remmod移除模块:格式rmmod <modulename>
实现一个简单的内核模块
-
hello.c模块代码
#define MODULE #include<linux/module.h> int init_module(void) { printk("<1>Hello World,created by zhangjie!\n"); return 0; } void cleanup_module(void) { printk("<1>GoodBye!\n"); } MODULE_LICENSE("GPL");说明:
- 任何模块程序的编写都需要包含linux/module.h这个头文件,这个文件包含了对模块的结构定义以及模块的版本控制。
- 函数init_module()和函数exit_module( )是模块编程中最基本的也是必须的两个函数。init_module()向内核注册模块所提供的新功能;exit_module()负责注销所有由模块注册的功能。
- 注意我们在这儿使用的是printk()函数(不要习惯性地写成printf),printk()函数是由Linux内核定义的,功能与printf相似。
-
Makefile文件:
TARGET = hello PWD :=$(shell pwd) KVER ?=$(shell uname -r) KDIR := /lib/modules/$(KVER)/build obj-m += $(TARGET).o default: make -C $(KDIR) M=$(PWD) modules -
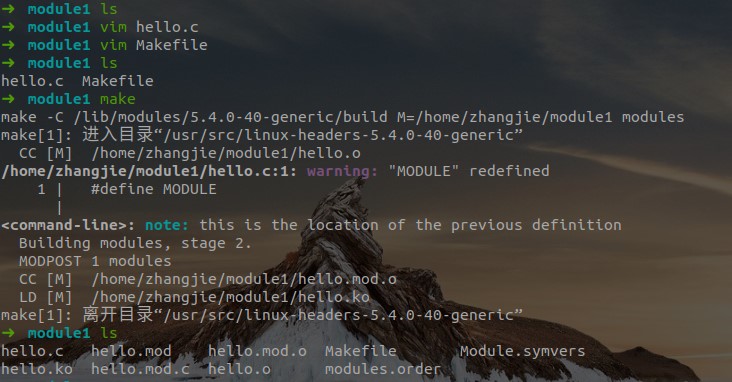
操作步骤:
- 在Makefile及hello.c所在目录下,直接
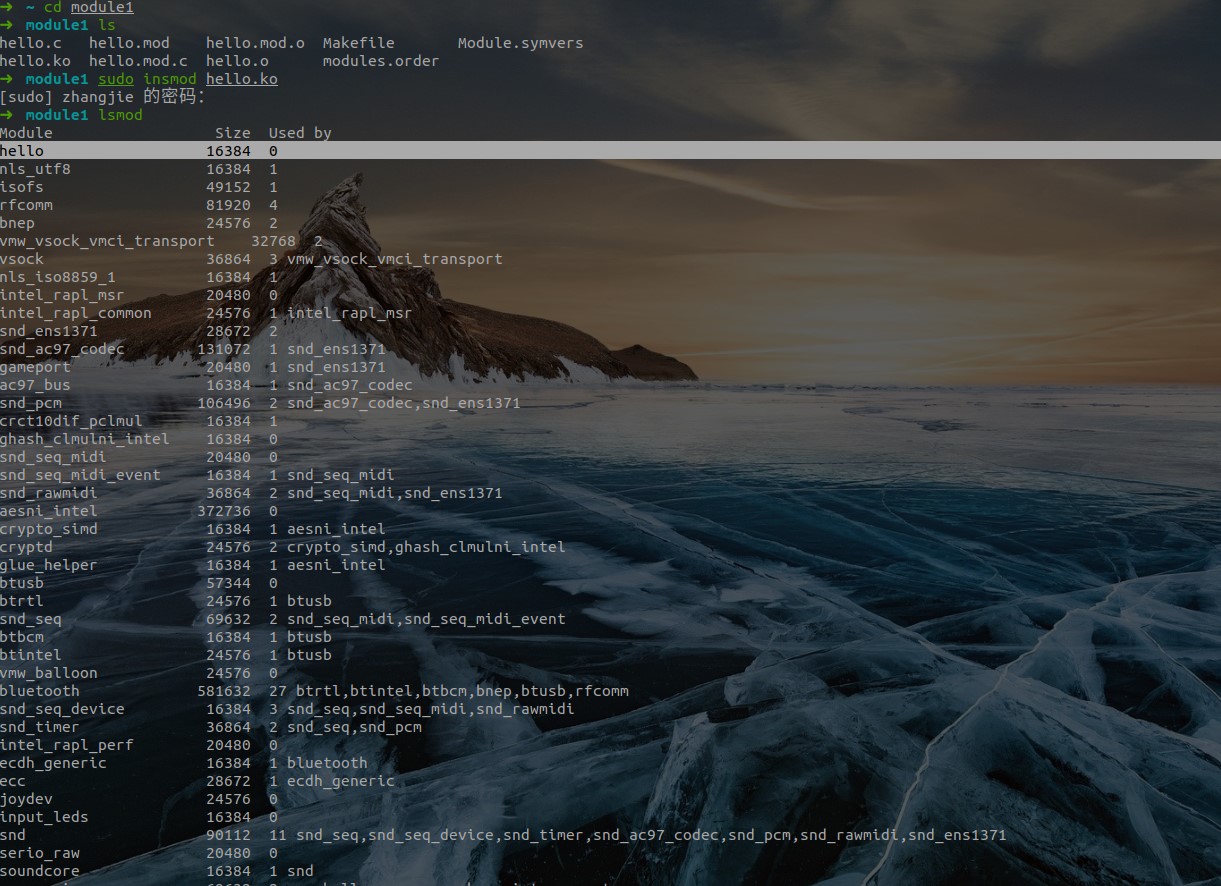
make,成功后查看当前目录下有无hello.ko文件产生,有则内核模块生成成功; - 使用
insmod命令,把此内核模块程序加载到内核中运行。结合lsmod,查看内核模块程序在内核中是否正确运行; - 查看内核模块程序打印的信息,使用
dmesg命令
- 在Makefile及hello.c所在目录下,直接
-
示例:
十二、Linux的信号机制
信号
信号是进程间一种有限的通信方式,用来提醒进程一件事情已经发生。 当一个信号发送给进程时,系统终端进程的控制流程,如果定义了进程的信号处理函数,则执行处理函数,否则执行默认的处理函数。
signal.h 中定义的信号如有:
SIGINT: 当用户希望中断进程时,SIGINT信号由用户的控制终端发送到进程。这通常通过按下Ctrl+C来发送,但是在某些系统中,可以使用“DELETE”键或“BREAK”键。SIGHUP: 检测到控制中断挂起或者控制进程死亡时,进程会收到 SIGHUP。现在操作系统,该信号通常意味着使用的 虚拟终端 已经被关闭。许多 守护进程 在接收到该信号时,会重载他们的设置和重新打开日志文件(logfiles),而不是去退出程序。nohup 命令用于无视该信号。SIGTSTP: 当用户希望挂起进程的时候,SIGTSTP信号由用户的控制终端发送到进程,通常通过按下 Ctrl + Z来发送,默认情况下会使进程暂停。SIGKILL: 发送SIGKILL信号到一个进程可以使其立即终止(KILL)。与SIGTERM和SIGINT相不同的是,这个信号不能被捕获或忽略,接收过程在接收到这个信号时不能执行任何清理。 以下例外情况适用:- 僵尸进程不能被杀死,因为它们已经死了,正在等待它们的父进程来收获它们。
- 处于阻塞状态的进程不会死亡,直到它们再次醒来。
- init 进程是特殊的: init不接收任何它不打算处理的信号,因此它会忽略SIGKILL。这条规则有一个例外,Linux 上的 init 如果被 ptrace 了,那么它是可以接收 SIGKILL 并被杀死的。
信号接收与处理
信号的接受与处理都在signal.h中
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
void handler(int signum)
{
if(signum == SIGINT)
printf("Recived SIGINT signal, ignoring...\n");
else if(signum == SIGHUP)
printf("Recived SIGHUP signal. ignoring...\n");
else if(signum == SIGTSTP)
printf("Recived SIGTSTP signal, ignoring...\n");
else
printf("Recived signal %d \n", signum);
}
int main()
{
signal(SIGINT, handler);
signal(SIGHUP, handler);
signal(SIGTSTP,handler);
printf("Waiting for signal... \n\n");
for(;;)
sleep(10000);
return 0;
}信号发送
信号发送通过kill() 就可实现。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
int main(int argc, char **argv)
{
if(argc != 2){
printf("A pid is needed\n");
return -1;
}
int pid = atoi(argv[1]);
if(pid < 0) {
printf("Pid is illgal\n");
return -1;
}
printf("Sending SIGINT signal...\n");
getchar();
kill(pid, SIGINT);
printf("Sending SIGHUP signal...\n");
getchar();
kill(pid, SIGHUP);
printf("Sending SIGTSTP signal...\n");
getchar();
kill(pid, SIGTSTP);
printf("Sending SIGKILL Signal...\n");
getchar();
kill(pid, SIGKILL);
return 0;
}中断
中断是一个打断正常工作流程的事件,由硬件设备,CPU或者软件产生。
中断可分为
- 同步: 通过一条指令产生
- 异步: 由外部指令产生
- 可屏蔽
- 不可屏蔽
同步中断,通常被称之为异常,是在处理器处理指令过程中产生的,例如除以0
异步中断,通常被称之为中断,由外部IO设备产生,例如网卡在收到数据包的时候会产生中断
异常
通常异常有两个来源
- 处理器检测到
- 错误
- 陷阱
- 中断
- 事先编程的
错误通常可以在执行指令之前可以检测到,通常可以纠正。而陷阱通常是指令运行后报告的异常。
中断的好处
中断可以用来提高计算机运行效率,增强计算功能。 如果没有中断,则处理器在与外部设备通行的过程中, 必须反复轮询设备是否完成动作, 造成了大量的处理器周期被浪费。 引入中断后, 设备可以主动发送中断信号给处理器, 提示处理器工作完成, 处理器就可以回过头来处理结果。 这样, 在设备处理的过程中, 处理器可以继续执行其他工作, 提高了运行效率
中断向量
- 每个中断和异常是由0~255之间的一个数来标识的,Intel把这个8位无符号整数叫做一个向量(vector)。非屏蔽中断的向量和异常的向量是固定的,而可屏蔽中断的向量是可以通过对中断控制器的编程来改变。
- 中断向量表
正如前面所说,中断和异常都是由一个中断向量来标识,在 Linux 中, 就有中断描述符表 (Interrupts Descriptor Table), 在arch/x86/include/asm/irq_vectors.h有详细的定义。
RTC
RTC 是硬件驱动的实时时钟
RTC 可以产生周期性的中断(不一定是秒,而是内部的频率), 也可产生定时的中断 (Alarm)
/dev/rtc或者/dev/rtcN 可以通过 ioctl 读取和控制, 相关接口可见 linux/rtc.h
#include <stdio.h>
#include <stdlib.h>
#include <linux/rtc.h>
#include <sys/ioctl.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
int main(int argc, char **argv)
{
int flag;
struct rtc_time rtc_current;
if(getuid()){
printf("\e[0;31m Root privilege is needed\n");
return -1;
}
if(argc != 2){
printf("\e[0;31m An argument is needed\n");
return -1;
}
char *rtc_dev = argv[1];
// Open RTC device
int fd = open(rtc_dev, O_RDONLY);
if(fd == -1) {
printf("\e[0;31m RTC Device open error\n");
return -1;
}
// Read current time
flag = ioctl(fd, RTC_RD_TIME, &rtc_current);
if(flag == -1) {
printf("\e[0;31m Can't read current time\n");
return -1;
}
printf("Current time %d-%d-%d, %02d:%02d:%02d \n",
rtc_current.tm_year + 1900, rtc_current.tm_mon + 1, rtc_current.tm_mday,
rtc_current.tm_hour, rtc_current.tm_min, rtc_current.tm_sec
);
// Set alarm 10 min later
rtc_current.tm_min += 10;
if(rtc_current.tm_min >= 60) {
rtc_current.tm_min = 0;
rtc_current.tm_hour += 1;
}
if(rtc_current.tm_hour == 24) {
rtc_current.tm_hour = 0;
}
flag = ioctl(fd, RTC_ALM_SET, &rtc_current);
if(flag == -1) {
printf("\e[0;31m Can't set alarm");
return -1;
}
// Read alarm settings
flag = ioctl(fd, RTC_ALM_READ, &rtc_current);
if(flag == -1) {
printf("\e[0;31m Can't read alarm");
return -1;
}
printf("Alarm on %d-%d-%d, %02d:%02d:%02d \n",
rtc_current.tm_year + 1900, rtc_current.tm_mon + 1, rtc_current.tm_mday,
rtc_current.tm_hour, rtc_current.tm_min, rtc_current.tm_sec
);
// Set alarm interrupt on
flag = ioctl(fd, RTC_AIE_ON, 0);
if(flag == -1) {
printf("\e[0;31m Can't set alarm interrupt on");
return -1;
}
// Waiting for alarm on
unsigned long interrupt;
flag = read(fd, &interrupt, sizeof(long));
if(flag == -1) {
printf("\e[0;31m Read alarm error\n");
return -1;
}
printf("Alarm rings!\n");
// Disable alrm interrupt
flag = (fd, RTC_AIE_OFF, 0);
if(flag == -1) {
printf("\e[0;31m Can't disable alarm interrupt\n");
return -1;
}
return 0;
}Linux报错解决
- E: 仓库 “http://ppa.launchpad.net/webupd8team/java/ubuntu eoan Release” 没有 Release 文件。
- 解决
Linux管道
- 管道是Linux由Unix那里继承过来的进程间的通信机制,它是Unix早期的一个重要通信机制。其思想是,在内存中创建一个共享文件,从而使通信双方利用这个共享文件来传递信息。由于这种方式具有单向传递数据的特点,所以这个作为传递消息的共享文件就叫做“管道”。
- 管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
- 管道命令使用
|作为界定符号 - 管道命令仅能处理standard output,对于standard error output会予以忽略。
- less,more,head,tail…都是可以接受standard input的命令,所以他们是管道命令
- 管道命令必须要能够接受来自前一个命令的数据成为standard input继续处理才行。
Linux网络操作
主机名配置
hostname:查看主机名;hostname 新的主机名:修改主机名,重启后无效
ip地址查看与配置
ifcofig可以查看和临时修改ip地址。
域名解析文件
/etc/hosts文件中有域名的配置文件。
网络服务管理
service network status:查看网络服务的状态service network stop:停止网络服务service network start:启动网络服务service network restart:重启网络服务service --status-all:查看系统中所有后台服务netstat -nltp:查看系统中网络进程的端口监听情况。
service iptables status:查看防火墙状态service iptables start:启动防火墙service iptables stop:关闭防火墙chkconfig iptables off:禁止防火墙自启
Linux的几种软件安装方式
- 二进制发布包:
- 软件已经针对具体的平台编译打包发布,只要解压,修改配置即可。
- RPM包:
1.软件已经根据redhat的包管理工具规范RPM打包发布,需要获取到相应软件的rpm包,然后用rpm命令安装。 - apt(apt-get)在线安装:(ubuntu系列)
apt-cache search soft注:soft是你要找的软件的名称或相关信息- 如果找到了软件soft.version,则用apt-get install soft.version命令安装软件
- 注:只要你可以上网,只需要用apt-cache search查找软件;
- 用apt-get install软件详细介绍:
- apt-get是debian,ubuntu发行版的包管理工具,与红帽中的yum工具非常类似。
- apt-get命令一般需要root权限执行,所以一般跟着sudo命令例sudo apt-get xxxx
- apt-get install packagename——安装一个新软件包(参见下文的aptitude)
- apt-get remove packagename——卸载一个已安装的软件包(保留配置文件)
- apt-get --purge remove packagename——卸载一个已安装的软件包(删除配置文件)
- dpkg --force-all --purge packagename ——有些软件很难卸载,而且还阻止了别的软件的应用,就可以用这个,不过有点冒险。
- apt-get autoremove——因为apt会把已装或已卸的软件都备份在硬盘上,所以如果需要空间的话,可以让这个命令来删除你已经删掉的软件。
- apt-get autoclean——定期运行这个命令来清除那些已经卸载的软件包的.deb文件。通过这种方式,可以释放大量的磁盘空间。如果需求十分迫切,可以使用apt-get clean以释放更多空间。这个命令会将已安装软件包裹的.deb文件一并删除。
- apt-get clean——这个命令会把安装的软件的备份也删除,不过这样不会影响软件的使用的。
- apt-get upgrade——更新所有已安装的软件包
- apt-get dist-upgrade——将系统升级到新版本
- apt-cache search string——在软件包列表中搜索字符串
- apt-cache showpkg pkgs——显示软件包信息。
- apt-cache stats——查看库里有多少软件
- apt-cache dumpavail——打印可用软件包列表。
- apt-cache show pkgs——显示软件包记录,类似于dpkg –print-avail。
- apt-cache pkgnames——打印软件包列表中所有软件包的名称
- 简单的说: dpkg只能安装已经下载到本地机器上的deb包. apt-get能在线下载并安装deb包,能更新系统,且还能自动处理包与包之间的依赖问题,这个是dpkg工具所不具备的。
- 源码编译安装:
- 软件以源码工程的形式发布,需要获取到源码工程后,用相应的开发工具进行编译打包部署。
- ubuntu安装本地
.deb包:dpkg -i deb包名- 如果出现缺少依赖的错误,则可以通过
apt-get upgrade -f来更新。
ftp/sftp文件传输
- 使用给予ftp或者sftp的工具进行客户端和服务端之间的文件传输。
- 如:filezilla,lrzsz,sftp等。